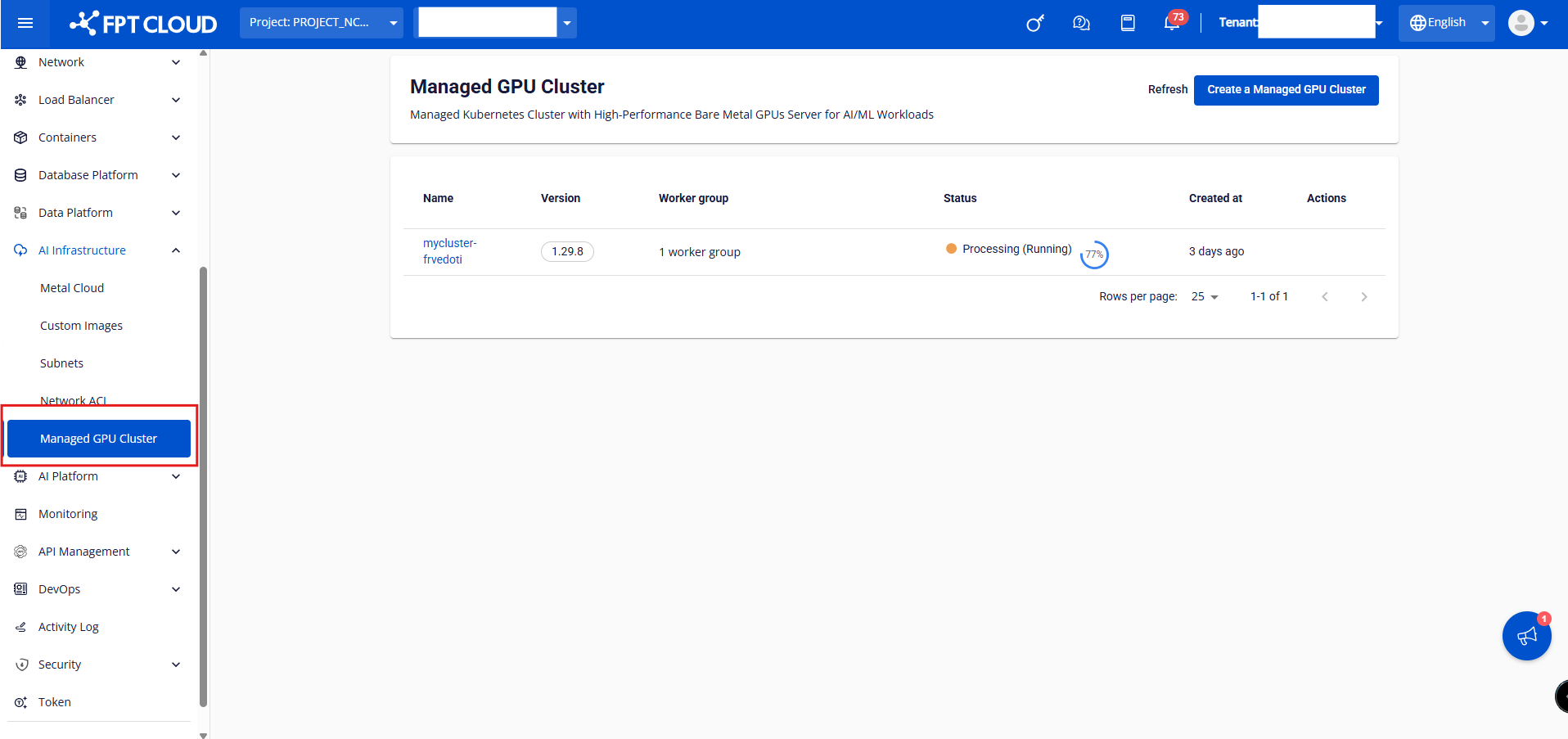
新 し い Managed Gpu ク ラ ス タ ー を 起 動
注意: この操作を実行するための必須条件は次のとおりです。 クォータ メタル クラウド (ベア メタル HPC) は、必要な数のクラスターを満たす必要 があります。少なくとも、 1つのの BMサーバーネットワーク 1つのロードバランサー用のネットワーク ステップ1: FPTポータルのメニューで、**[AIインフラストラクチャ] >[マネージドGPUクラスター]> 「マネージド GPU クラスターを作成する」**を選択します。
ステップ2: クラスターの[一般情報]タブに情報を入力し、[次へ] ボタンをクリックします。
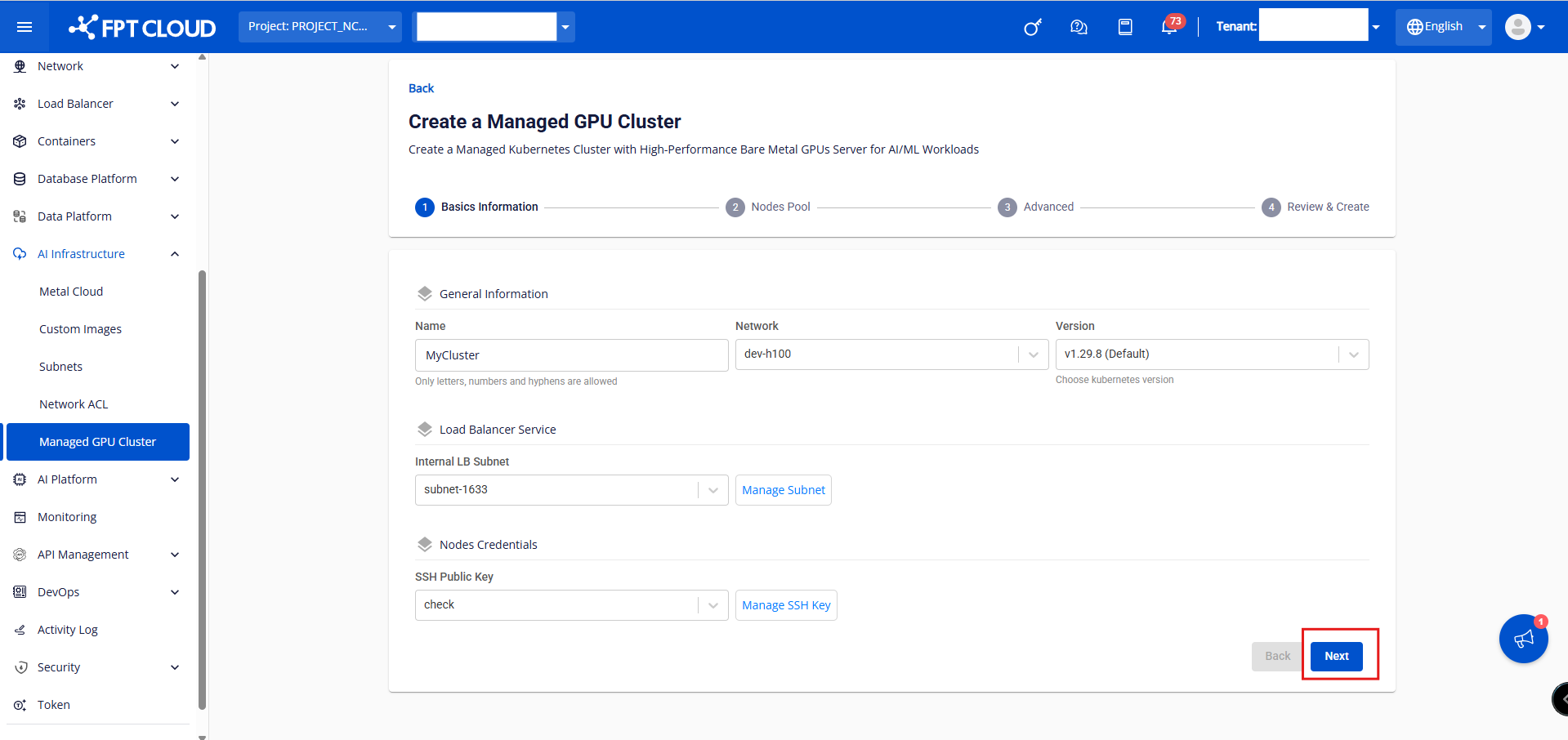
- 一般情報:
- 名前: クラスターの名前を入力します。クラスターの名前は異なり、ルールに従っている必要があります。
- ネットワーク: ベアメタルGPUサーバーの作成されたサブネット範囲から選択します。
- バージョン: お客様のアプリケーションに適した Kubernetes のバージョンを選択します。
- 内部LBサブネット: ロードバランサータイプのサービスにプライベートIPレンジを設定します。
- SSH 公開鍵: クラスタのワーカーノードに SSH で接続するための SSHキー
ステップ3: クラスターの[Nodes Pool]タブに情報を入力し、[次へ] ボタンをクリック します。クラスターマネージドGPUクラスターを作成する際の注意点:
- マネージド GPU クラスターは 、同じ構成のワーカー ノードのグループであるワーカー グループを通じてワーカー ノードを管理します。ユーザーは、適切なアプリケーションに対してワーカーグループを分割できます。システムには少なくとも 1つのワーカー グループ (ベース) が必要であり、ユーザーはこのワーカーグループを削除できません。
- ワーカーグループ設定セクションでは、ユーザーは目的のワーカーグループにラベルを割り当てることができます。このラベルは、ワーカー グループ内のすべてのワーカー ノードに適用されます。ユーザーは、ラベルの追加や削除を行ったり、既存のラベルのキー/値を編集したりできます。これらのラベルにより、ユーザーはニーズに応じてアプリケーションを別々のワーカーグループに簡単にデプロイできます。
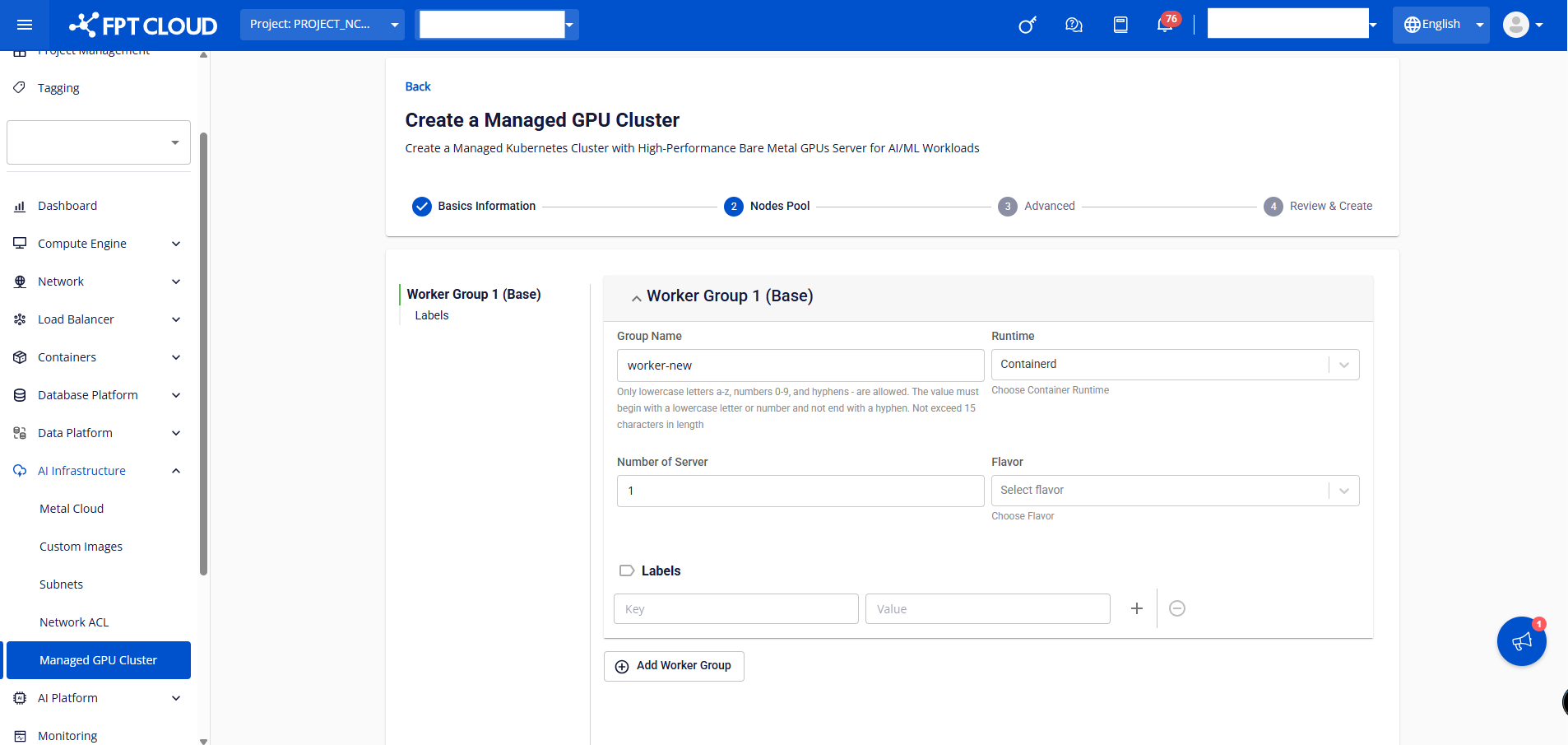
➤ ワーカーグループ1(ベース) : • グループ名: ワーカーグループを区別するために、ワーカー・グループに名前を付けます。 • ランタイム: ランタイム コンテナを選択します。現在、新しいシステムはContainerd ランタイム コンテナのみをサポートしています。 • サーバー数: クラスタ内のワーカーを実行するために作成された MetalCloud Server の数。 • フレーバー: Metal クラウド GPU サーバーのフレーバー タイプで、デフォルトはH100 です。 • ラベル: ワーカーグループ内のすべてのワーカーにKubernetes のラベルをつけます。 ユーザーは、k8s クラスターを初期化するときに**[ワーカー グループの追加]** ボタンをクリックしてワーカー グループを追加できます。
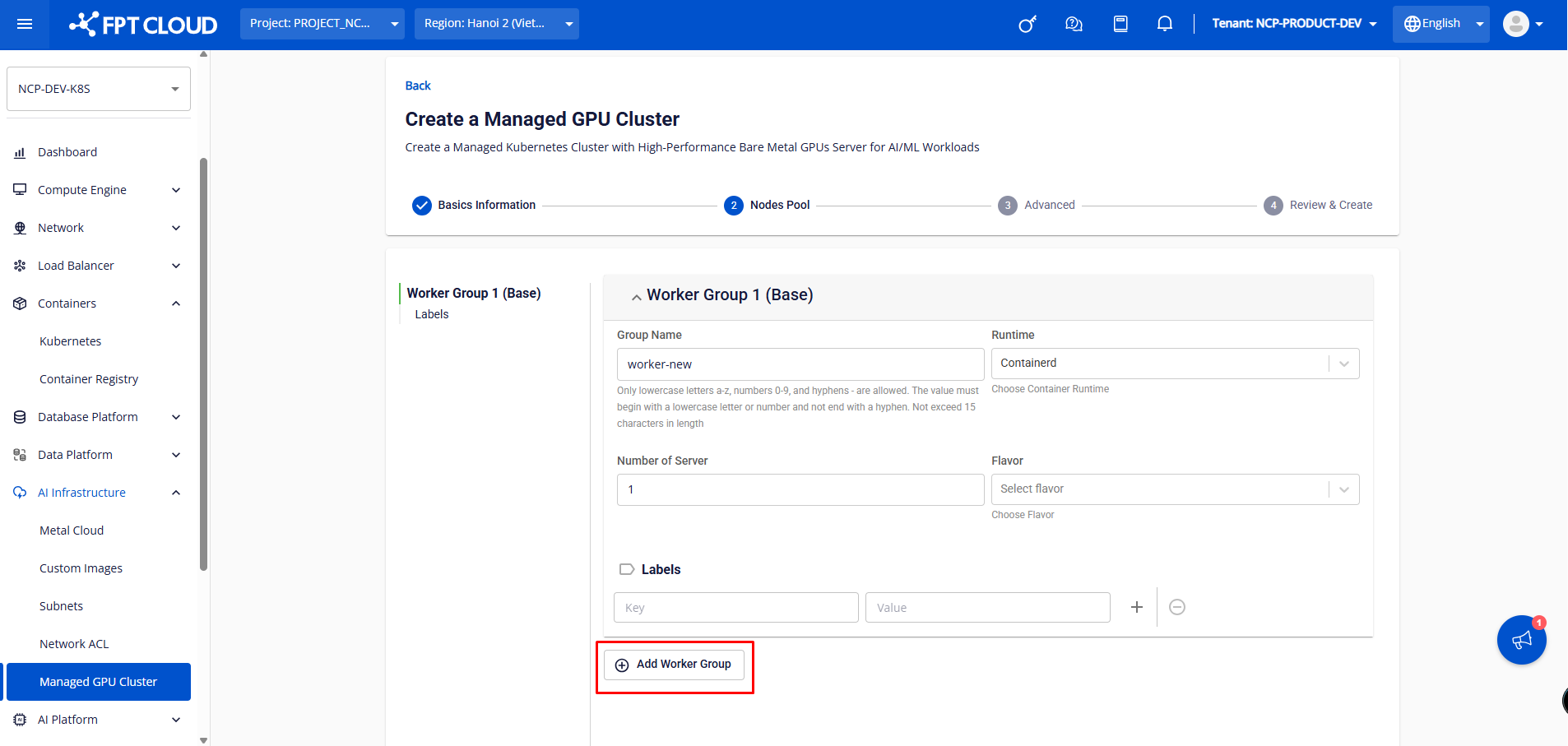
さらに、ワーカー グループ 2 以降、ユーザーはワーカー ノードでアプリケーションをスケジュールする目的で、ワーカー グループのテイントを構成できます。テイントは、簡単に追加、削除、編集することもできます。
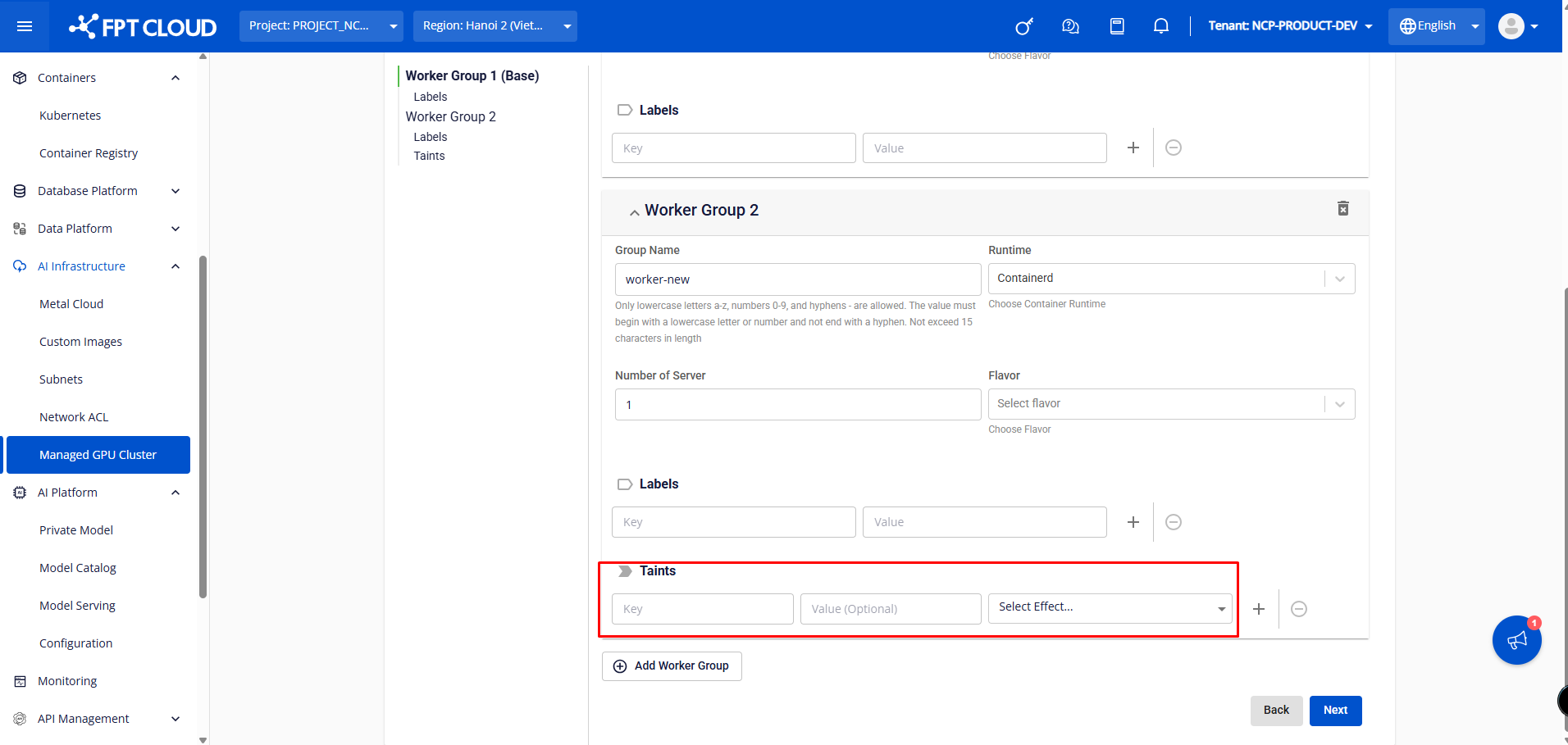
注: Unify Portal でワーカー グループのラベル/テイントを設定するユーザーは、kubectl を使用してそのワーカー グループ内のノードのラベル/テイントを削除できません (システムは Unify Portal の設定に従ってノードのラベル/テイントを自動的に再追加します) ため、Unify Portal でラベル/テイント設定を削除する必要があります。 ➤ ワーカーグループ : ユーザーは、K8sクラスターを初期化するときに[ワーカーグループの追加]ボタンをクリックしてワーカーグループを追加できます。 さらに、Worker Group 2 以降では、Worker ノードでアプリケーションをスケジュールする目的で、Worker グループのテイントを設定できます。テイントは、簡単に追加、削除、編集することもできます。 Taintsの詳細については 、こちらをご覧ください 注: ポータルでワーカー グループのラベル/テイントを構成するユーザーは、kubectl でそのワーカー グループ内のノードのラベル/テイントを削除できません (ポータルの構成に従って、システムのノードに対するラベル/テイントが自動的に再追加されます) ため、ポータルでラベル/テイント構成を削除する必要があります。 ステップ4: [詳細設定]
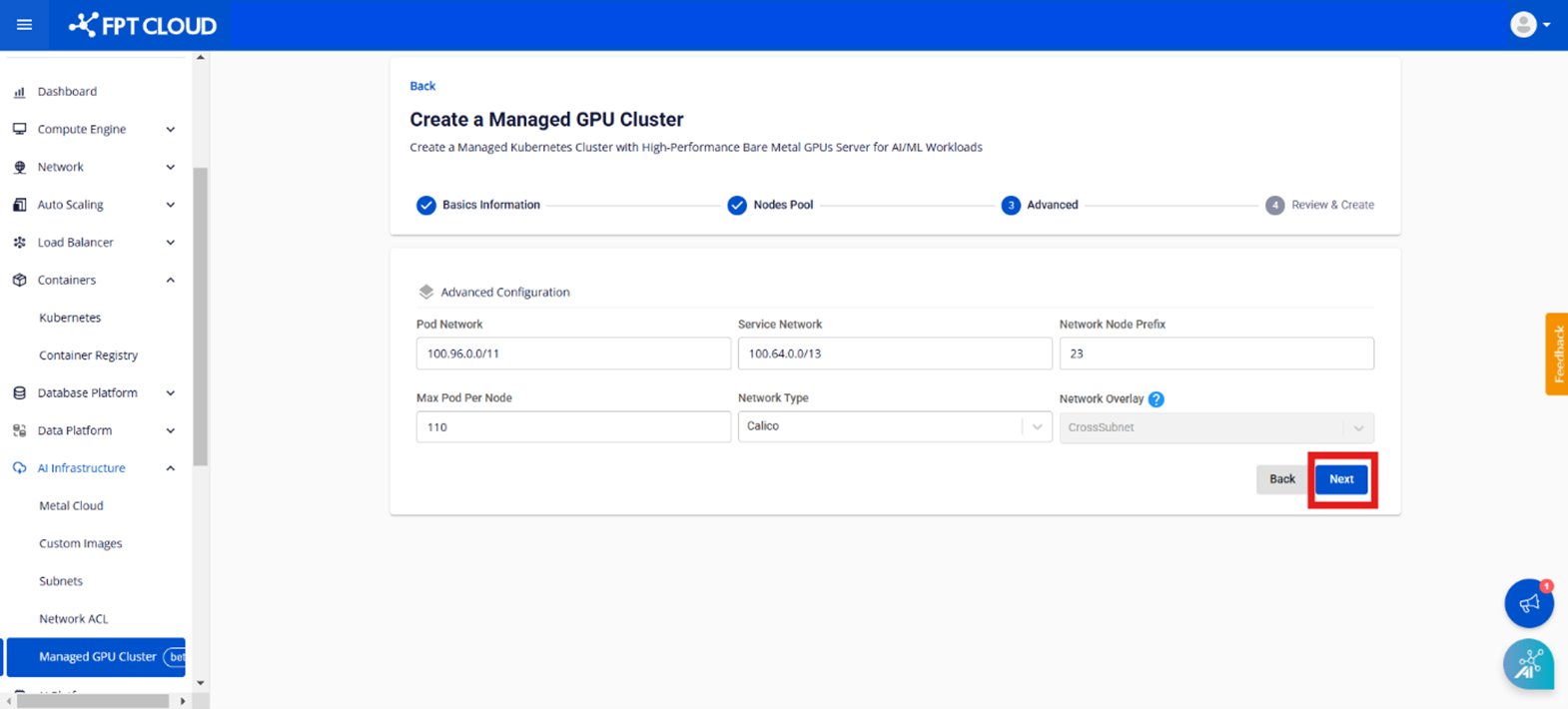
- Pod Network: クラスター内のポッドに使用されるネットワーク。
- サービスネットワーク:クラスタのサービスに使用されるネットワーク。
- Network Node Prefix: Managed GPU ノードあたりのポッドの最大数。
- Max Pod per Node: クラスターに設定される CNI タイプ、Calico タイプのみがサポートされています
ステップ5: Review & Create画面には、以前に設定されたユーザークラスタ情報が表示され、システムはクラスタを初期化するのに十分なベアメタルGPUサーバークォータがあるかどうかを自動的にチェックします。
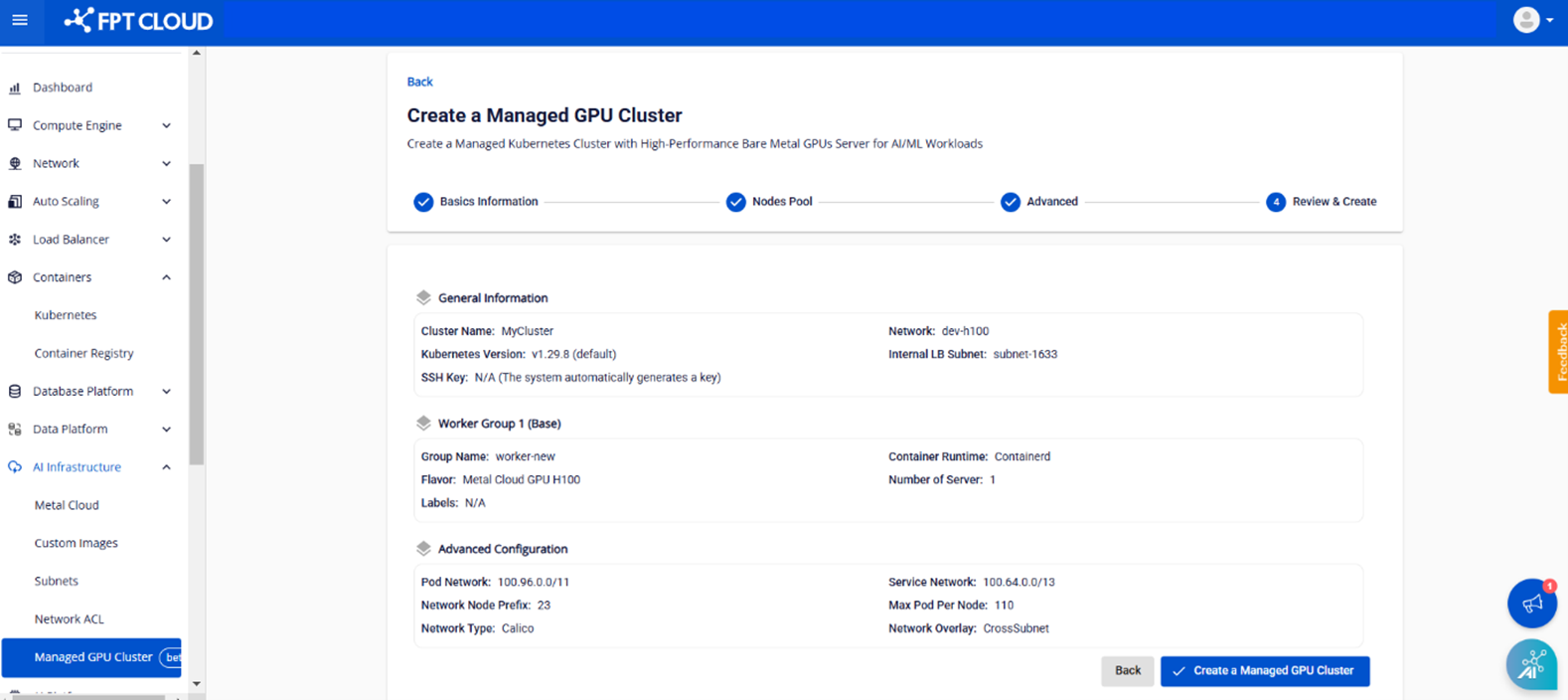
システムがリソースを正常にチェックしたら、[マネージド GPU クラスターの作成] ボタンをクリックして、クラスターの作成に進みます。