データセットの選択
まず最初に、意図したユースケースでのモデルのパフォーマンスに直接影響するため、最適なデータセットを準備する必要があります。 優れたデータセット品質によって実現できること:
- 残存する問題に対処するための例を収集する。
- モデルが特定の側面でまだ十分でない場合は、それらの側面を正しく実行する方法を直接示すトレーニング例を追加してください。
- 既存の例の問題点を精査する。
- モデルに文法、論理、スタイルの問題がある場合は、データに同様の問題がないか確認してください。例えば、モデルが「このミーティングをスケジュールします」(本来すべきでない場合)と言うようになった場合、既存の例がモデルに実行できない新しいことができると教えていないか確認してください。
- データのバランスと多様性を考慮する。
- データ内のアシスタント応答の 60% が「これには答えられません」と言っているのに、推論時に応答の 5% だけがそう言うべき場合、拒否が過剰になる可能性があります。
- トレーニング例に応答に必要なすべての情報が含まれていることを確認する。
- 会話の中に見つからない特徴に基づいてモデルがユーザーを褒めるように学習させたい場合、モデルが情報をハルシネーションする可能性があります。
- トレーニング例の一致性と一貫性を確認する。
- 複数の人がトレーニングデータを作成した場合、モデルのパフォーマンスは人々の間の一致度と一貫性のレベルによって制限される可能性があります。例えば、テキスト抽出タスクで人々が抽出したスニペットの 70% しか一致しない場合、モデルはこれを超えることができない可能性があります。
- すべてのトレーニング例が推論時に期待されるのと同じ形式であることを確認する。
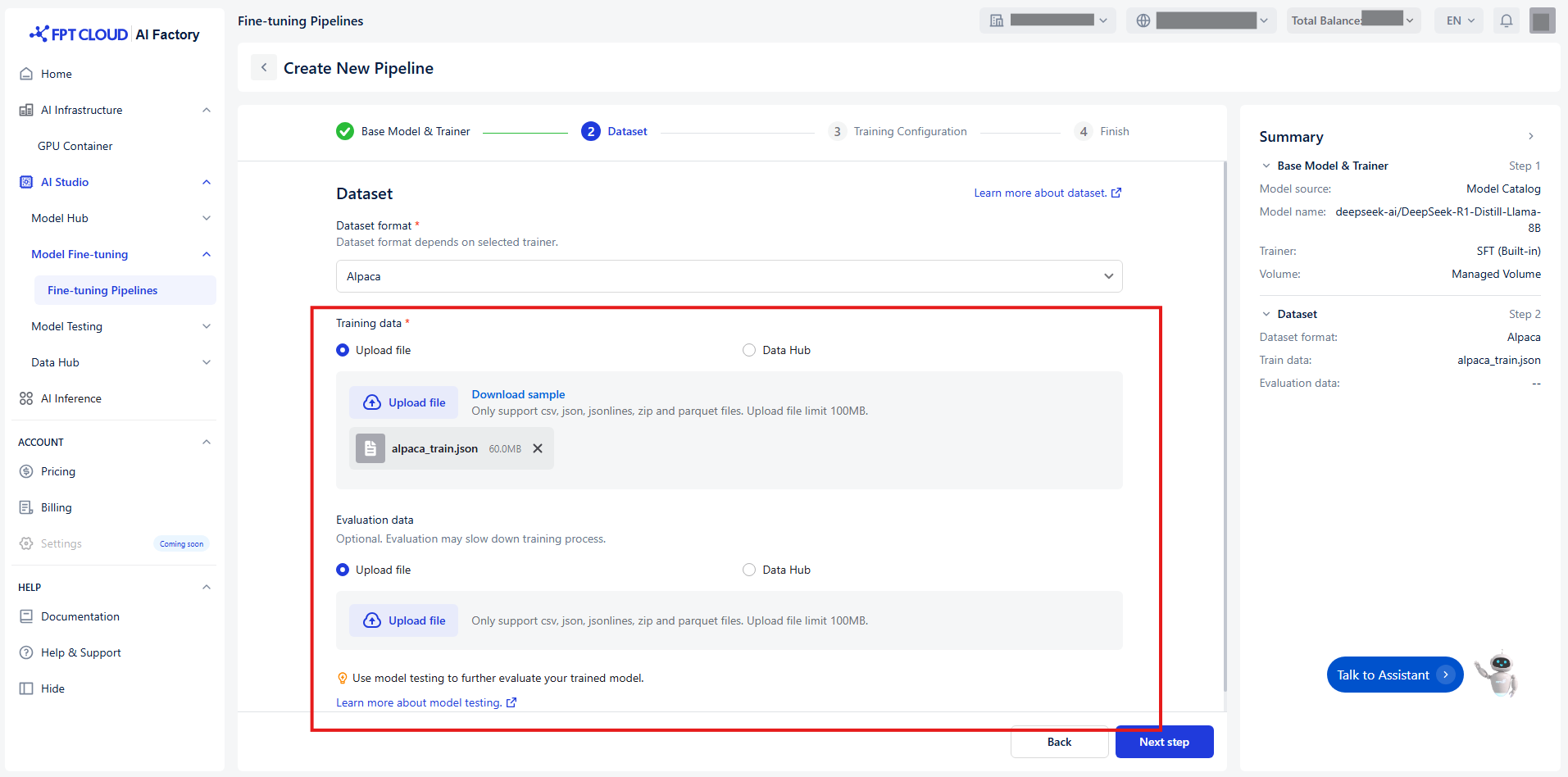
Training data と Evaluation data を転送する方法は 2 つあります:
- ファイルのアップロード
- デフォルト値は Upload file です。
- コンピュータからローカルファイルを選択します。
- (オプション)Download sample をクリックして、期待される形式の例を確認できます。
注意: ファイルが選択したデータ形式と一致していることを確認してください。
| Trainer | 対応データ形式 | 対応ファイル形式 | 対応ファイルサイズ |
|---|---|---|---|
| SFT | Alpaca | CSV | |
| JSON | |||
| JSONLINES | |||
| ZIP | |||
| PARQUET | 100MB まで | ||
| SFT | ShareGPT | JSON | |
| JSONLINES | |||
| ZIP | |||
| PARQUET | 100MB まで | ||
| SFT | ShareGPT_Image | ZIP | |
| PARQUET | 100MB まで | ||
| DPO | ShareGPT | JSON | |
| JSONLINES | |||
| ZIP | |||
| PARQUET | 100MB まで | ||
| Pre-training | Corpus | TXT | |
| JSON | |||
| JSONLINES | |||
| ZIP | |||
| PARQUET | 100MB まで |
- Data Hub への接続
- Data Hub をクリックします。
- Data Hub から接続またはデータセットを選択します。注意: データセットが選択した形式と互換性があることを確認してください。
- (オプション)Open Data Hub をクリックしてデータセットをプレビューまたは管理できます。
- (オプション)Reload アイコン をクリックして接続とデータセットの一覧を更新できます。
- Data Hub の詳細ガイドに従ってください。