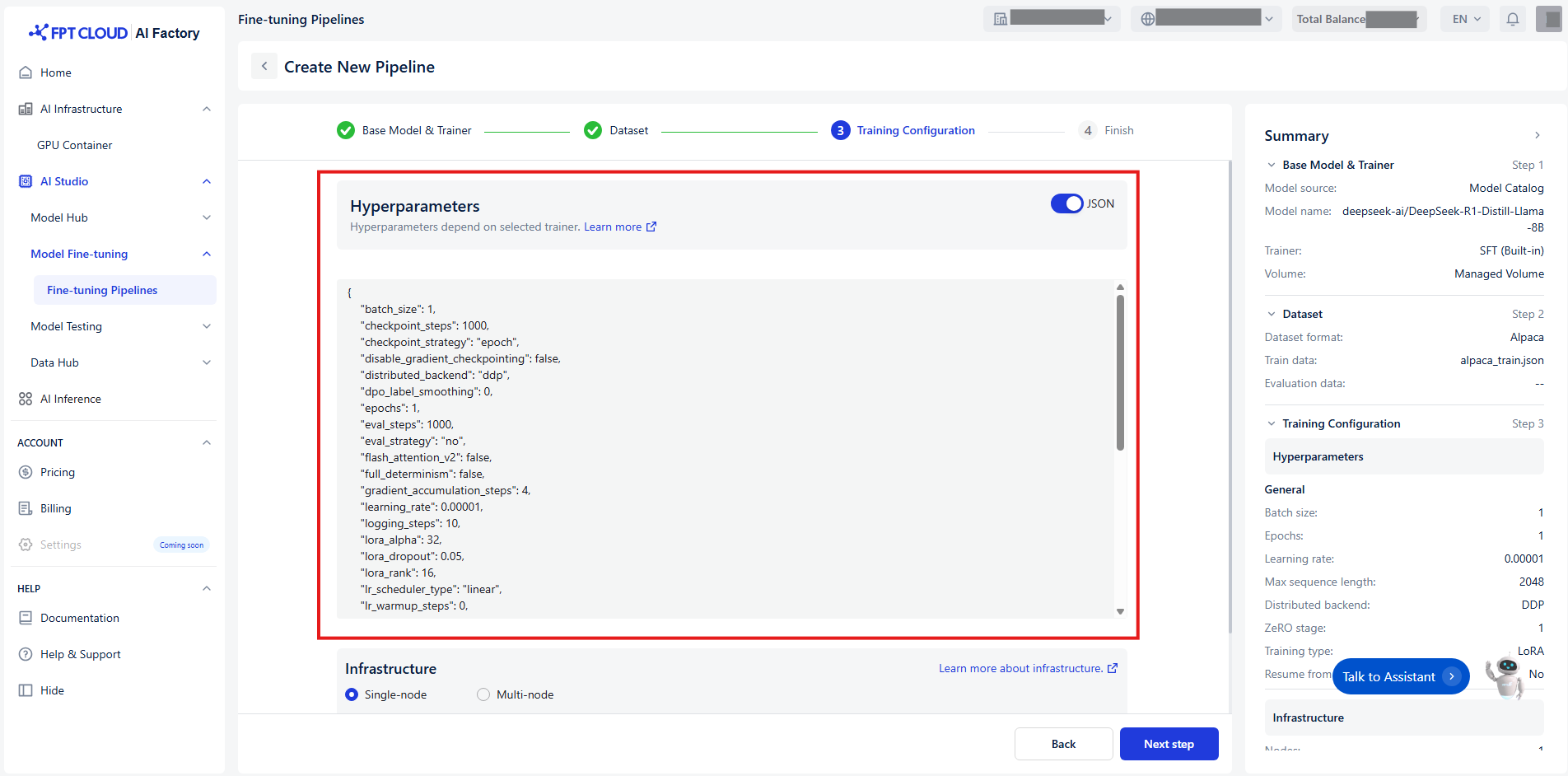
ハイパーパラメータの設定
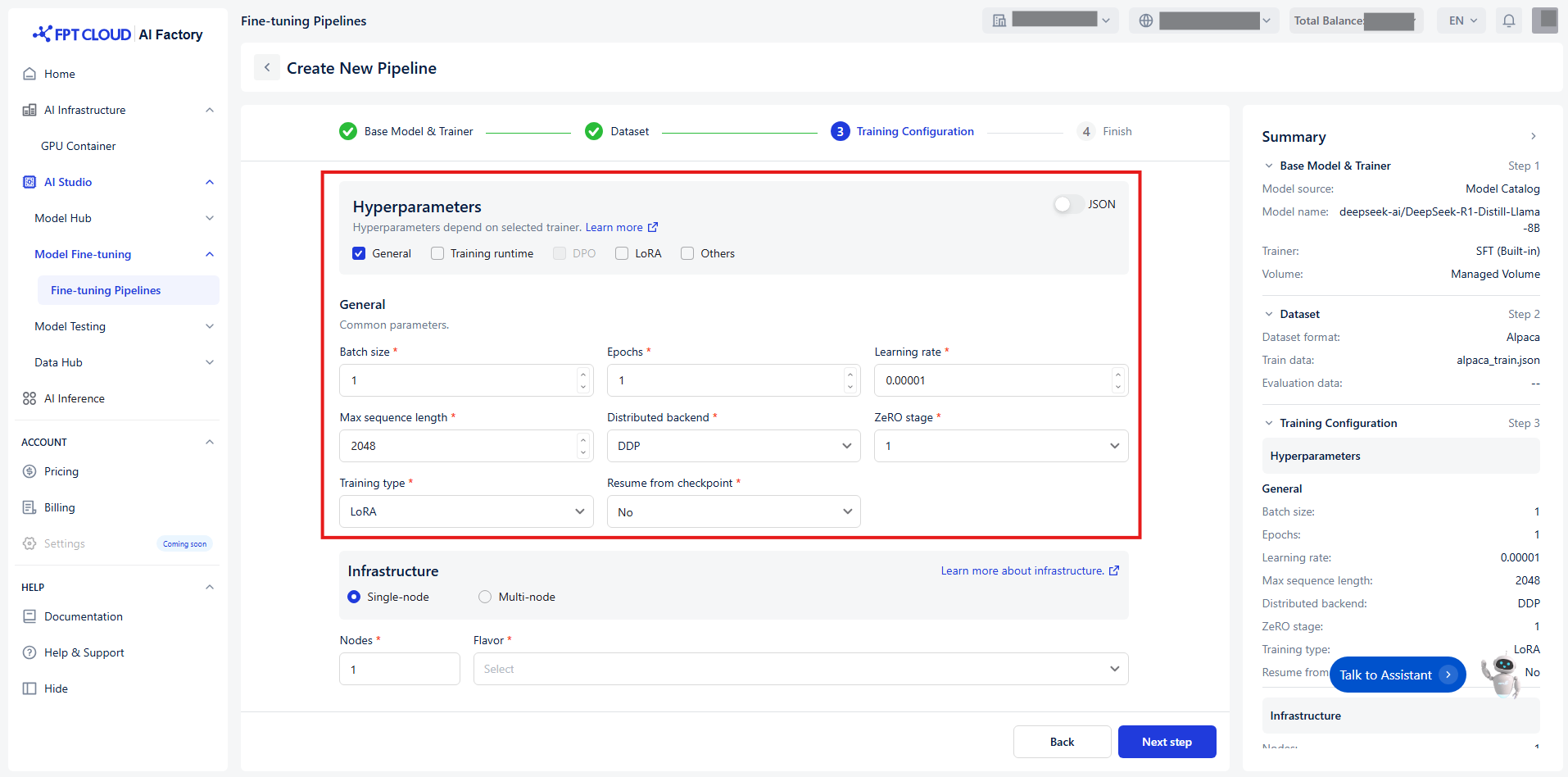
ハイパーパラメータはトレーニングプロセス中にモデルの重みを更新する方法を制御します。設定を容易にするために、機能と関連性に基づいてハイパーパラメータを 5 つの明確なグループ に分類しています:
グループ 1 - General
トレーニングプロセスのコア設定です。
| 名前 | 説明 | 型 | サポートされる値 |
|---|---|---|---|
| Batch size | 重みを更新する前に 1 回の順伝播・逆伝播でモデルが処理する例の数です。バッチが大きいとトレーニングが遅くなりますが、より安定した結果が得られる場合があります。分散トレーニングの場合、これは各デバイスのバッチサイズです。 | Int | [1, +∞) |
| Epochs | エポックはモデルトレーニング中にトレーニングデータ全体を 1 回通過することです。モデルが反復的に重みを調整できるよう、通常は複数のエポックを実行します。 | Int | [1, +∞) |
| Learning rate | モデルの学習済みパラメータへの変更の大きさを調整します。 | Float | (0, 1) |
| Max sequence length | 最大入力長で、これより長いシーケンスはこの値で切り捨てられます。 | Int | [1, +∞) |
| Distributed backend | 分散トレーニングに使用するバックエンドです。 | Enum[string] | DDP, DeepSpeed |
| ZeRO stage | DeepSpeed ZeRO アルゴリズムを適用するステージです。Distributed backend = DeepSpeed の場合のみ適用されます。 | Enum[int] | 1, 2, 3 |
| Training type | 使用するパラメータモードです。 | Enum[string] | Full, LoRA |
| Resume from checkpoint | トレーニングエンジンが再開するチェックポイントの相対パスです。 | Union[bool, string] | No, Last checkpoint, Path/to/checkpoint |
グループ 2 - Training runtime
トレーニングの効率とパフォーマンスを最適化します。
| 名前 | 説明 | 型 | サポートされる値 |
|---|---|---|---|
| Gradient accumulation steps | 逆伝播/更新パスを実行する前にグラデーションを累積する更新ステップ数です。 | Int | [1, +∞) |
| Mixed precision | 使用する混合精度の種類です。 | Enum[string] | Bf16, Fp16, None |
| Quantization bit | オンザフライ量子化を使用してモデルを量子化するビット数です。現在は Training type = LoRA の場合のみ適用されます。 | Enum[string] | None |
| Optimizer | トレーニングに使用するオプティマイザーです。 | Enum[string] | Adamw, Sgd |
| Weight decay | オプティマイザーに適用する重み減衰です。 | Float | [0, +∞) |
| Max gradient norm | 勾配クリッピングの最大ノルムです。 | Float | [0, +∞) |
| Disable gradient checkpointing | 勾配チェックポイントを無効にするかどうかです。 | Bool | True, False |
| Flash attention v2 | Flash Attention バージョン 2 を使用するかどうかです。現在は false のみサポートしています。 | Bool | False |
| LR warmup steps | 0 から Learning rate まで線形ウォームアップに使用するステップ数です。 | Int | [0, +∞) |
| LR warmup ratio | 線形ウォームアップに使用するトレーニング総ステップ数の比率です。 | Float | [0, 1) |
| LR scheduler | 使用する学習率スケジューラーです。 | Enum[string] | Linear, Cosine, Constant |
| Full determinism | 分散トレーニングで再現可能な結果を確保します。重要: これはパフォーマンスに悪影響を与えるため、デバッグ時のみ使用してください。True の場合、Seed の設定は無効になります。 | Bool | True, False |
| Seed | 再現性のためのランダムシードです。 | Int | [0, +∞) |
グループ 3 - DPO
trainer = DPO を使用する場合にこのグループを有効にします。
| 名前 | 説明 | 型 | サポートされる値 |
|---|---|---|---|
| DPO label smoothing | DPO のロバスト DPO ラベルスムージングパラメータで、0 から 0.5 の間である必要があります。 | Float | [0, 0.5] |
| Preference beta | 優先損失のベータパラメータです。 | Float | [0, 1] |
| Preference fine-tuning mix | DPO トレーニングにおける SFT 損失係数です。 | Float | [0, 10] |
| Preference loss | 使用する DPO 損失の種類です。 | Enum[string] | Sigmoid, Hinge, Ipo, Kto pair, Orpo, Simpo |
| SimPO gamma | SimPO 損失のターゲット報酬マージンです。該当する場合のみ使用されます。 | Float | (0, +∞) |
グループ 4 - LoRA
Training type = LoRA を使用する場合にこのグループを有効にします。
| 名前 | 説明 | 型 | サポートされる値 |
|---|---|---|---|
| Merge adapter | LoRA アダプターをベースモデルにマージして最終モデルを提供するかどうかです。マージしない場合、トレーニング完了後に LoRA アダプターのみが保存されます。 | Bool | True, False |
| LoRA alpha | LoRA のアルファパラメータです。 | Int | [1, +∞) |
| LoRA dropout | LoRA のドロップアウト率です。 | Float | [0, 1] |
| LoRA rank | LoRA 行列のランクです。 | Int | [1, +∞) |
| Target modules | 量子化またはファインチューニングのターゲットモジュールです。 | String | All linear |
グループ 5 - Others
ファインチューニングの進捗を追跡・保存する方法を制御します。
| 名前 | 説明 | 型 | サポートされる値 |
|---|---|---|---|
| Checkpoint strategy | トレーニング中に採用するチェックポイント保存戦略です。「best」は Evaluation strategy が「no」でない場合のみ適用されます。 | Enum[string] | No, Epoch, Steps |
| Checkpoint steps | Checkpoint strategy = step の場合、2 回のチェックポイント保存間のトレーニングステップ数です。 | Int | [1, +∞) |
| Evaluation strategy | トレーニング中に採用する評価戦略です。 | Enum[string] | No, Epoch, Steps |
| Evaluation steps | Evaluation strategy = steps の場合、2 回の評価間の更新ステップ数です。設定されていない場合、Logging steps と同じ値がデフォルトになります。 | Int | [1, +∞) |
| No. of checkpoints | 値が渡された場合、チェックポイントの総数を制限します。 | Int | [1, +∞) |
| Save best checkpoint | 最良のチェックポイントを追跡・保持するかどうかです。現在は False のみサポートしています。 | Bool | False |
| Logging steps | stdout ログと MLflow データポイントを含むログイベント間のステップ数です。Logging steps = -1 は毎ステップにログを記録することを意味します。 | Int | [0, +∞) |
| または toggle JSON に切り替えることでハイパーパラメータを素早く設定できます: |