Select Base Model
Retrieve base models from the Model Hub in two ways:
- Model Catalog: A repository of model sources from various providers such as DeepSeek, Gemma, Llama, and Qwen.
- Private Model: A repository for user-owned models and fine-tuned models.
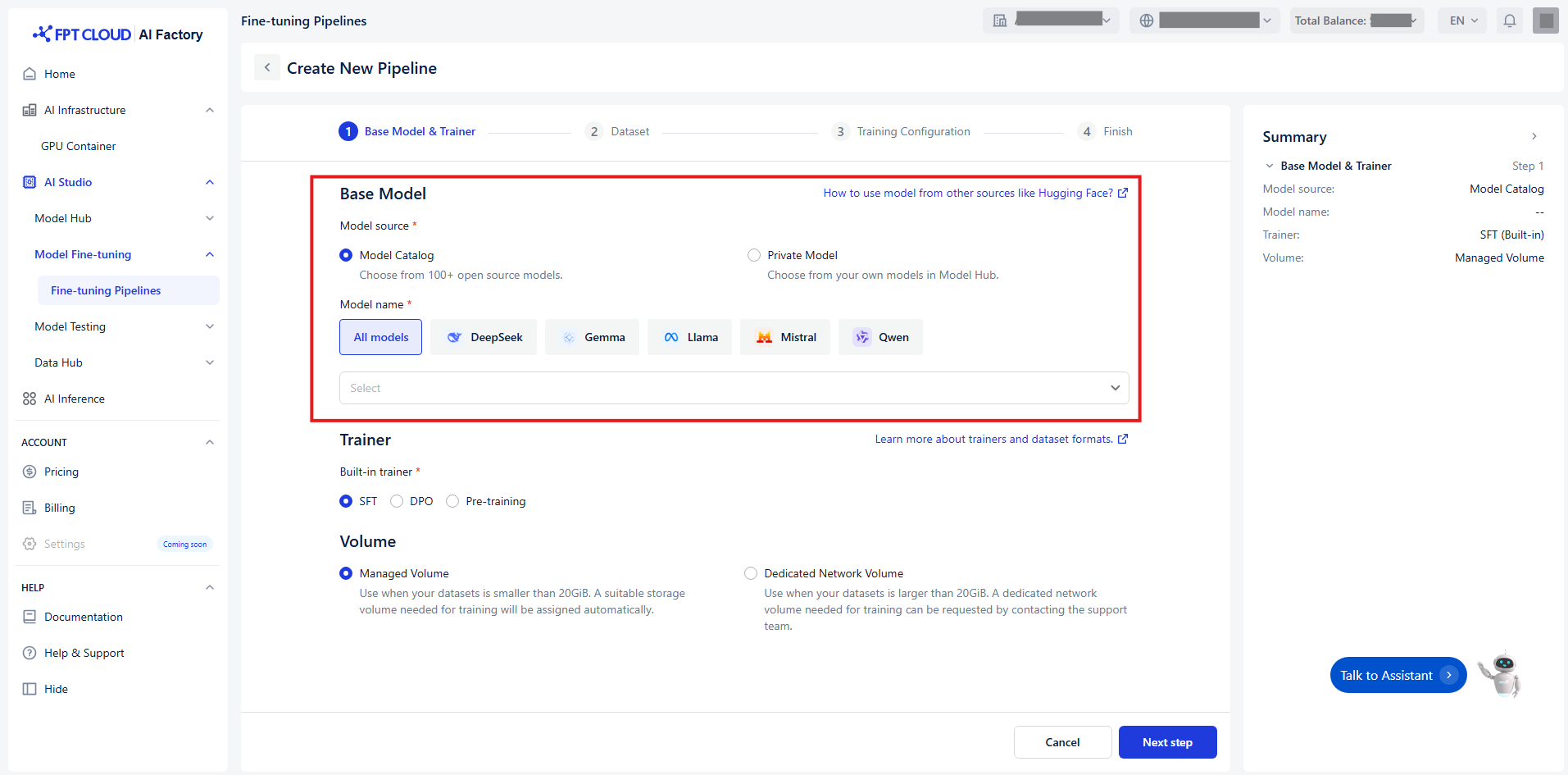
The Model Catalog includes the following models:
| Base model | Model family | Model type | Model size | Learning stage |
|---|---|---|---|---|
| deepseek-ai/DeepSeek-R1-Distill-Llama-70B | DeepSeek | LLM | 70B | Instruction-tuned |
| deepseek-ai/DeepSeek-R1-Distill-Llama-8B | DeepSeek | LLM | 8B | Instruction-tuned |
| deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B | DeepSeek | LLM | 1.5B | Instruction-tuned |
| deepseek-ai/DeepSeek-R1-Distill-Qwen-14B | DeepSeek | LLM | 14B | Instruction-tuned |
| deepseek-ai/DeepSeek-R1-Distill-Qwen-32B | DeepSeek | LLM | 32B | Instruction-tuned |
| deepseek-ai/DeepSeek-R1-Distill-Qwen-7B | DeepSeek | LLM | 7B | Instruction-tuned |
| google/gemma-3-12b-it | Gemma | LLM | 2B | Instruction-tuned |
| google/gemma-3-12b-pt | Gemma | LLM | 2B | Pre-trained |
| google/gemma-3-1b-it | Gemma | LLM | 1B | Instruction-tuned |
| google/gemma-3-1b-pt | Gemma | LLM | 1B | Pre-trained |
| google/gemma-3-27b-it | Gemma | LLM | 27B | Instruction-tuned |
| google/gemma-3-27b-pt | Gemma | LLM | 27B | Pre-trained |
| google/gemma-3-4b-it | Gemma | LLM | 4B | Instruction-tuned |
| google/medgemma-27b-text-it | Gemma | LLM (Medical) | 27B | Instruction-tuned |
| meta-llama/Llama-3.1-70B | Llama | LLM | 70B | Pre-trained |
| meta-llama/Llama-3.1-70B-Instruct | Llama | LLM | 70B | Instruction-tuned |
| meta-llama/Llama-3.1-8B | Llama | LLM | 8B | Pre-trained |
| meta-llama/Llama-3.1-8B-Instruct | Llama | LLM | 8B | Instruction-tuned |
| meta-llama/Llama-3.2-1B | Llama | LLM | 1B | Pre-trained |
| meta-llama/Llama-3.2-1B-Instruct | Llama | LLM | 1B | Instruction-tuned |
| meta-llama/Llama-3.2-3B | Llama | LLM | 3B | Pre-trained |
| meta-llama/Llama-3.2-3B-Instruct | Llama | LLM | 3B | Instruction-tuned |
| meta-llama/Llama-3.3-70B-Instruct | Llama | LLM | 70B | Instruction-tuned |
| mistralai/Mixtral-8x7B-Instruct-v0.1 | Mistral | MoE LLM | 8x7B | Instruction-tuned |
| mistralai/Mixtral-8x7B-v0.1 | Mistral | MoE LLM | 8x7B | Pre-trained |
| Qwen/Qwen2-0.5B | Qwen | LLM | 0.5B | Pre-trained |
| Qwen/Qwen2-0.5B-Instruct | Qwen | LLM | 0.5B | Instruction-tuned |
| Qwen/Qwen2-1.5B | Qwen | LLM | 1.5B | Pre-trained |
| Qwen/Qwen2-1.5B-Instruct | Qwen | LLM | 1.5B | Instruction-tuned |
| Qwen/Qwen2-72B | Qwen | LLM | 72B | Pre-trained |
| Qwen/Qwen2-72B-Instruct | Qwen | LLM | 72B | Instruction-tuned |
| Qwen/Qwen2-7B | Qwen | LLM | 7B | Pre-trained |
| Qwen/Qwen2-7B-Instruct | Qwen | LLM | 7B | Instruction-tuned |
| Qwen/Qwen2-VL-2B | Qwen | VLM | 2B | Pre-trained |
| Qwen/Qwen2-VL-2B-Instruct | Qwen | VLM | 2B | Instruction-tuned |
| Qwen/Qwen2-VL-72B | Qwen | VLM | 72B | Pre-trained |
| Qwen/Qwen2-VL-72B-Instruct | Qwen | VLM | 72B | Instruction-tuned |
| Qwen/Qwen2-VL-7B | Qwen | VLM | 7B | Pre-trained |
| Qwen/Qwen2-VL-7B-Instruct | Qwen | VLM | 7B | Instruction-tuned |
| Qwen/Qwen2.5-0.5B | Qwen | LLM | 0.5B | Pre-trained |
| Qwen/Qwen2.5-0.5B-Instruct | Qwen | LLM | 0.5B | Instruction-tuned |
| Qwen/Qwen2.5-1.5B | Qwen | LLM | 1.5B | Pre-trained |
| Qwen/Qwen2.5-1.5B-Instruct | Qwen | LLM | 1.5B | Instruction-tuned |
| Qwen/Qwen2.5-14B | Qwen | LLM | 14B | Pre-trained |
| Qwen/Qwen2.5-14B-Instruct | Qwen | LLM | 14B | Instruction-tuned |
| Qwen/Qwen2.5-32B | Qwen | LLM | 32B | Pre-trained |
| Qwen/Qwen2.5-32B-Instruct | Qwen | LLM | 32B | Instruction-tuned |
| Qwen/Qwen2.5-3B | Qwen | LLM | 3B | Pre-trained |
| Qwen/Qwen2.5-3B-Instruct | Qwen | LLM | 3B | Instruction-tuned |
| Qwen/Qwen2.5-72B | Qwen | LLM | 72B | Pre-trained |
| Qwen/Qwen2.5-72B-Instruct | Qwen | LLM | 72B | Instruction-tuned |
| Qwen/Qwen2.5-7B | Qwen | LLM | 7B | Pre-trained |
| Qwen/Qwen2.5-7B-Instruct | Qwen | LLM | 7B | Instruction-tuned |
| Qwen/Qwen2.5-VL-32B-Instruct | Qwen | VLM | 32B | Instruction-tuned |
| Qwen/Qwen2.5-VL-3B-Instruct | Qwen | VLM | 3B | Instruction-tuned |
| Qwen/Qwen2.5-VL-72B-Instruct | Qwen | VLM | 72B | Instruction-tuned |
| Qwen/Qwen2.5-VL-7B-Instruct | Qwen | VLM | 7B | Instruction-tuned |
| Qwen/Qwen3-0.6B | Qwen | LLM | 0.6B | Pre-trained |
| Qwen/Qwen3-1.7B | Qwen | LLM | 1.7B | Pre-trained |
| Qwen/Qwen3-14B | Qwen | LLM | 14B | Pre-trained |
| Qwen/Qwen3-30B-A3B | Qwen | LLM | 30B | Pre-trained |
| Qwen/Qwen3-32B | Qwen | LLM | 32B | Pre-trained |
| Qwen/Qwen3-4B | Qwen | LLM | 4B | Pre-trained |
| Qwen/Qwen3-8B | Qwen | LLM | 8B | Pre-trained |
| The Private Model , if you want to upload your models, please contact us or follow the guide upload model through SDK |