Vllm Use Cases Gpt Oss
はじめに
GPT-OSSはOpenAIの最新のオープンウェイトモデルシリーズで、強力な推論、エージェントタスク、多様な開発者ユースケース向けに設計されています。必要事項:
- openai/gpt-oss-20b:低レイテンシ、ローカルまたは特殊なユースケース向け
- より小さいモデル
- 約16GB VRAMのみ必要
- openai/gpt-oss-120b:本番環境、汎用、高度な推論ユースケースに推奨
- フルサイズの大型モデル
- ≥60GB VRAMが最適
- 単一のH100または複数GPUセットアップに収まります
ステップ1:vLLM v0.10.1テンプレートでコンテナをデプロイする
- 新しいコンテナを作成するボタンをクリックします
- テンプレート選択で、最新のvLLMテンプレート(v0.10.1)を選択します。
- GPUの選択では、モデルの提供に1xH100 GPUのみ必要です
- openai/gpt-oss-20bを提供したい場合は、他の設定をすべてデフォルトのままにしてください。openai/gpt-oss-120bを提供したい場合はモデルを変更してください。
- 「コンテナを作成」をクリックしてコンテナを作成します。
コンテナの初期化を待ちます。このプロセスは通常、gpt-oss-20bモデルのダウンロードに約15分、gpt-oss-120bモデルには最大2時間かかります。進捗はコンテナログで監視できます。
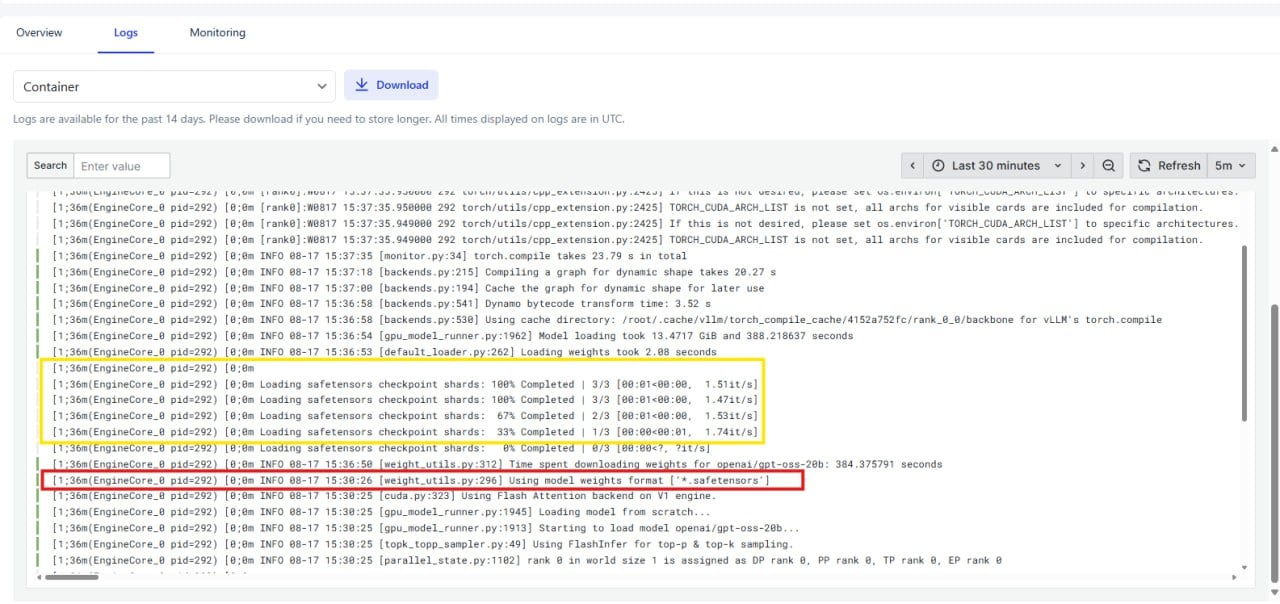
ログが以下のような行(スクリーンショットの赤いボックス)で停止している場合
Using model weights format [*.safetensors]
これはモデルがまだダウンロードまたは初期化中であり、エンドポイントがまだリクエストを受け付ける準備ができていないことを意味します。 モデルはすべてのチェックポイントシャードが完了したときにのみ、完全にロードされてサービスを提供する準備ができたと見なされます(スクリーンショットの黄色いボックス)
Loading safetensors checkpoint shards: 100% Completed [3/3]
これはすべてのモデルファイルが正常にロードされたことを示します。
ステップ2:実行リクエストを送信する
コンテナが実行中でモデルがダウンロードされたら、セットアップをテストするために実行リクエストを送信できます。
- 利用可能なモデル一覧を確認する。
curl -X 'GET' \
'{your endpoint}/v1/models' \ -H 'accept: application/json'.fptcloud.com/v1/models' \
-H 'accept: application/json'
- いくつかの簡単な質問でモデルをテストする。
curl -X 'POST' \
'{your endpoint}/v1/chat/completions' \88sdgk-8000.serverless.fptcloud.com/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"messages": [
{
"content": "Tell me what is GPT-OSS?",
"role": "user",
"name": "admin"
}
],
"model": " openai/gpt-oss-120b"
}'
!(/img/migrated/information-fill-1-30ad0c7d.png)
注意: 両モデルともharmonyレスポンスフォーマットでトレーニングされており、harmonyフォーマットでのみ使用する必要があります。それ以外では正常に動作しません。
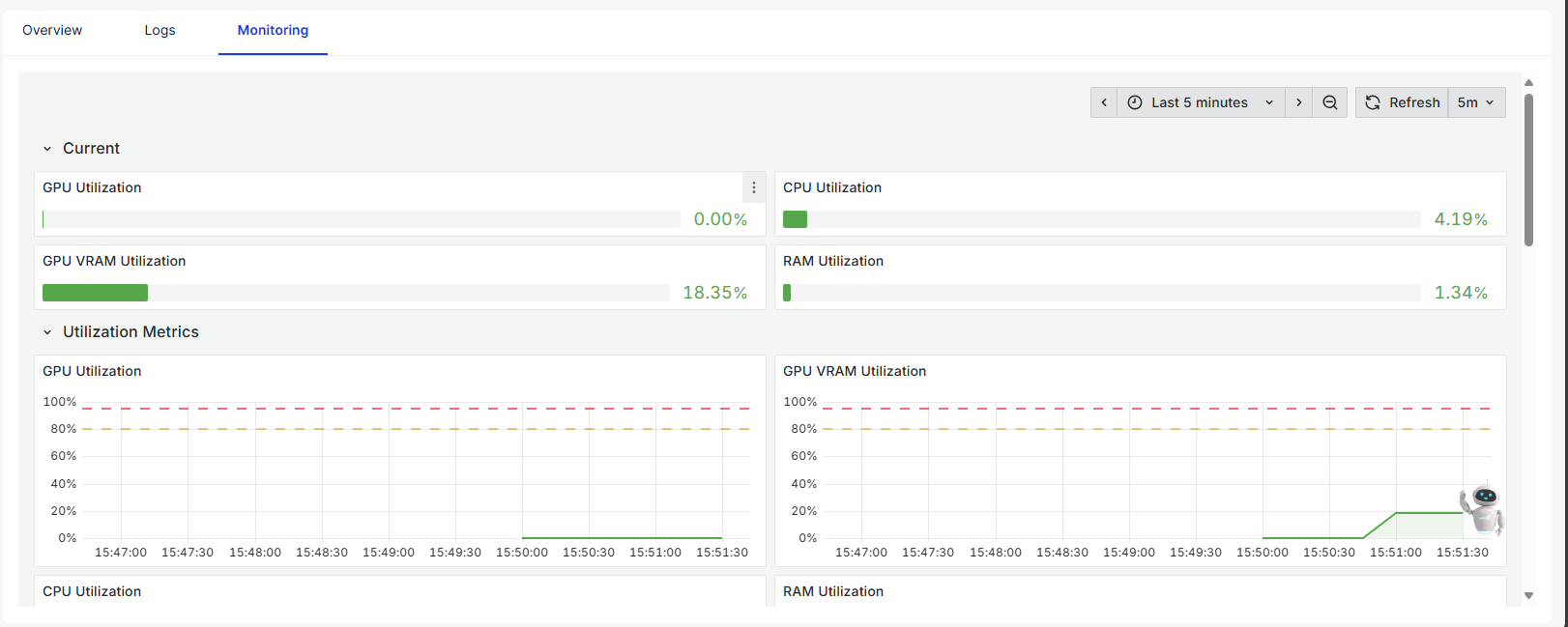
モニタリング機能を使用して、コンテナ化されたサービスのパフォーマンス、可用性、リソース使用状況を追跡し、問題の検出と運用の最適化に役立てることができます。