Load fine-tuned model and tokenizer
Code ServerでGLUE MRPCのBERTをファインチューニングする
このガイドでは、GPU対応のCode ServerコンテナでGLUE MRPCタスクに事前学習済みBERTモデルをファインチューニングする方法を説明します。
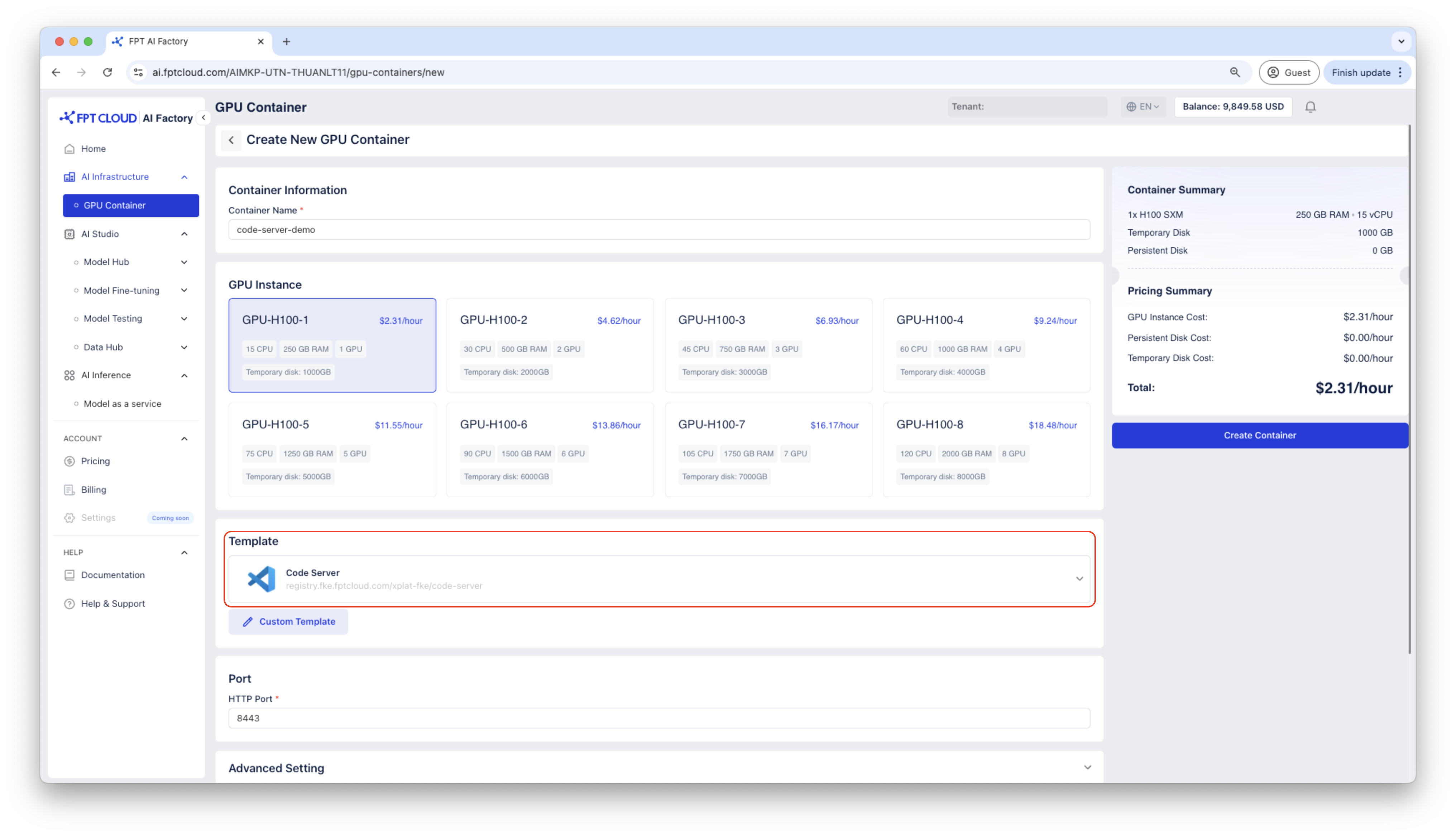
ステップ1:GPU Containerを作成する
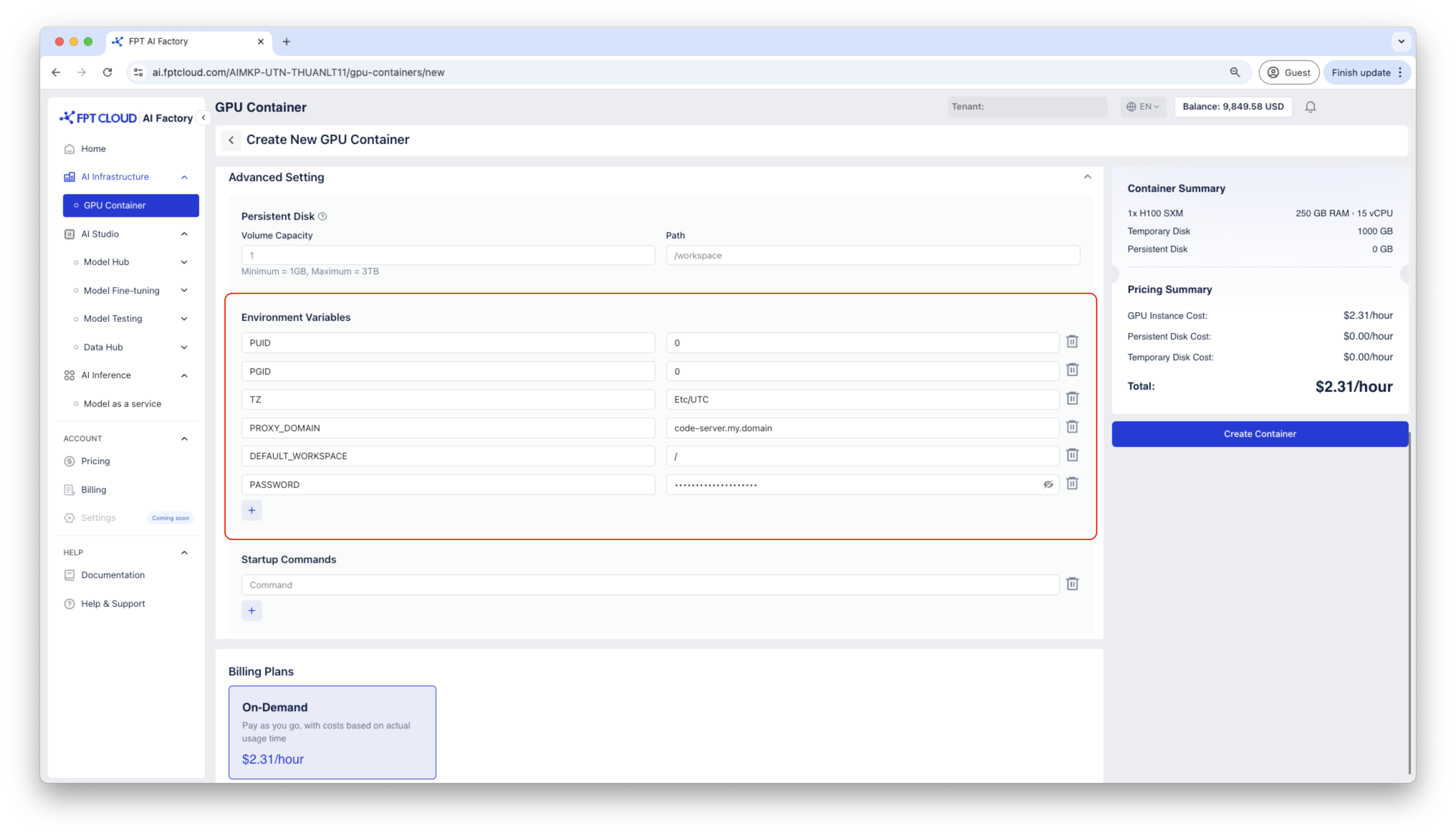
Code ServerテンプレートでContainerを作成します。
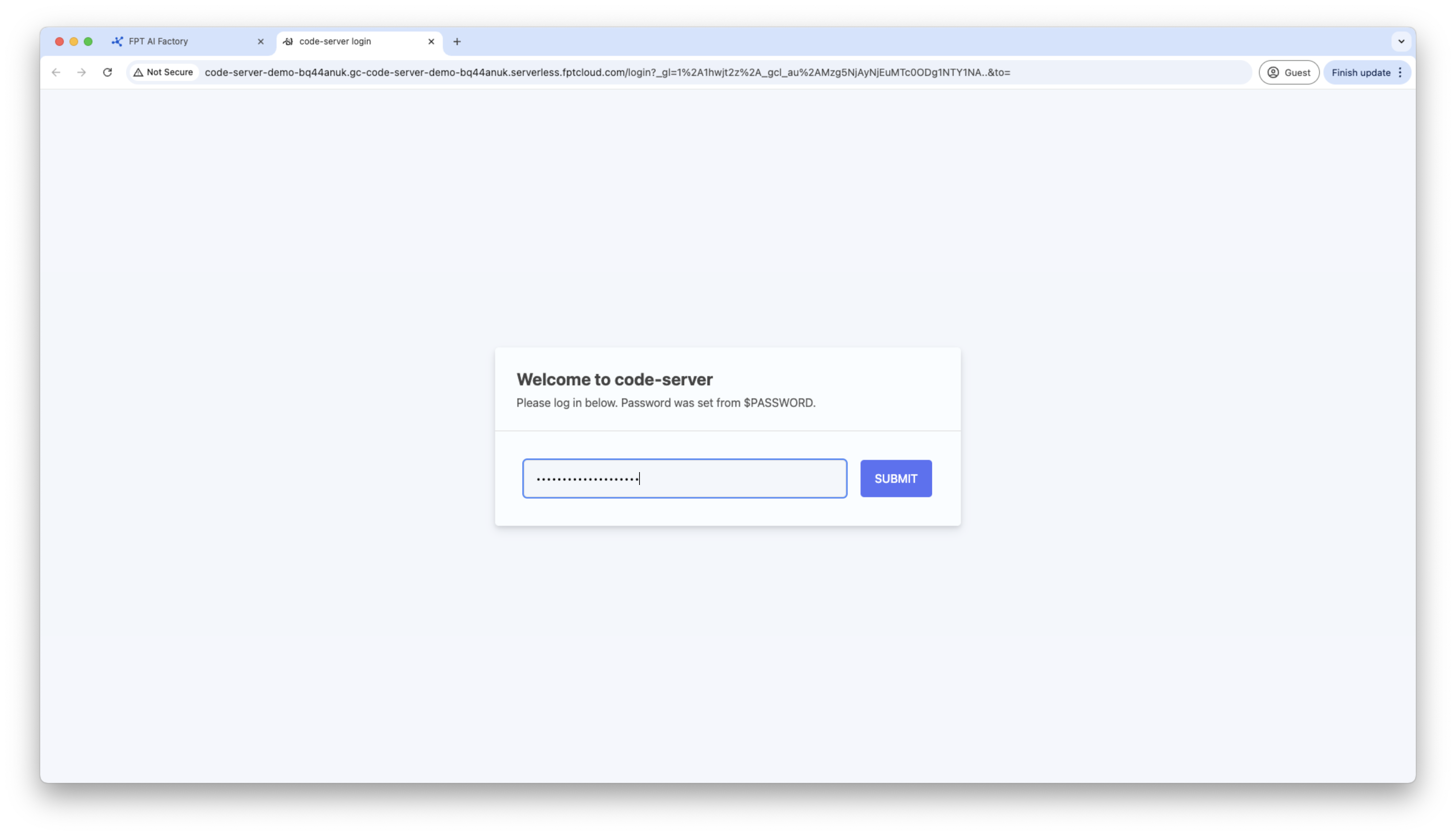
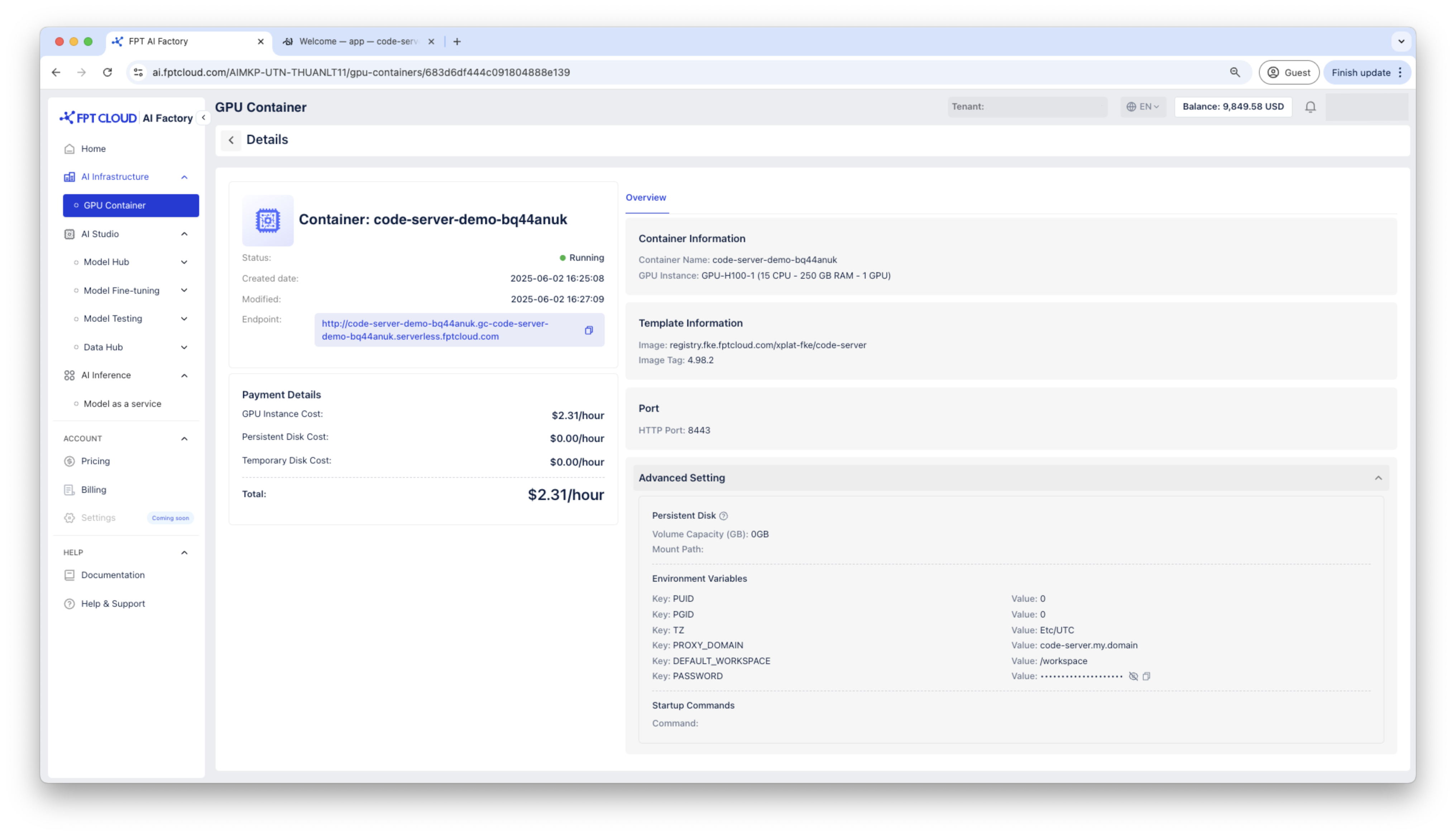 HTTPエンドポイント経由でContainerにアクセスします。Code ServerコンテナはパスワードAdを要求するため、コンテナの詳細で生成されたパスワードを使用して接続してください。
HTTPエンドポイント経由でContainerにアクセスします。Code ServerコンテナはパスワードAdを要求するため、コンテナの詳細で生成されたパスワードを使用して接続してください。
ステップ2:python3、pipをインストールする
sudo apt update && sudo apt install -y python3 python3-pip python3-venv git
ステップ3:仮想環境を有効化する
仮想環境を使用して必要なpythonパッケージをインストールし、トレーニングコードを実行します
python3 -m venv ~/venv
source ~/venv/bin/activate
ステップ4:必要なpythonパッケージをインストールする
pip install --upgrade pip
pip install scikit-learn scipy
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install datasets evaluate accelerate
ステップ5:GithubからHugging Face transformersをクローンする
cd /workspace
git clone https://github.com/huggingface/transformers.git
pip install –e .
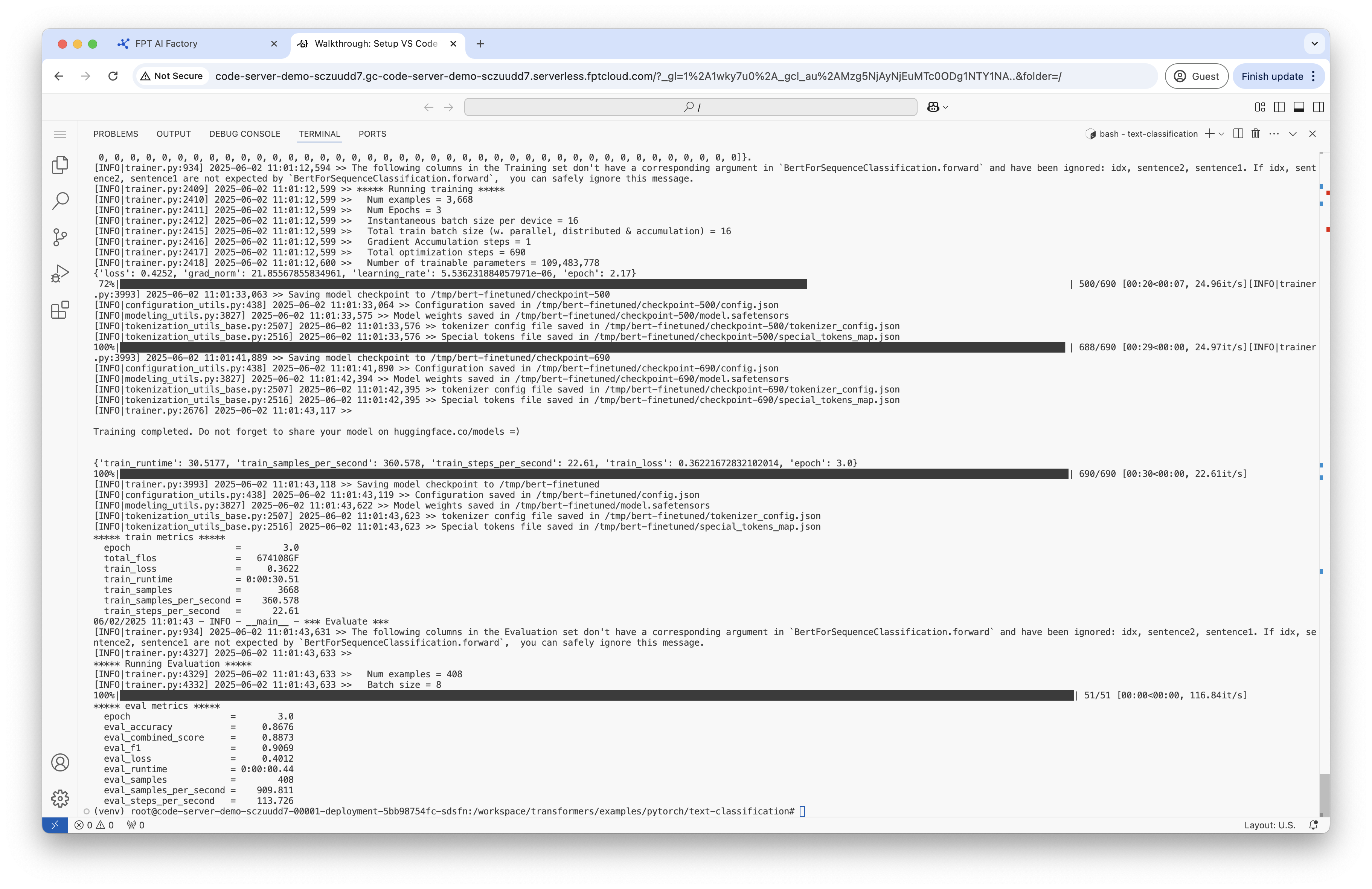
ステップ6:GLUE MRPCでBERTをファインチューニングする
出力は /tmp/bert-finetuned に保存されます。このステップでは、GLUEベンチマークのMicrosoft Research Paraphrase Corpus(MRPC)タスクで事前学習済みBERTモデルをファインチューニングします。これにより、モデルは2つの文が言い換え(同じ意味)かどうかを分類することを学習します。
cd /workspace/transformers/examples/pytorch/text-classification
python3 run_glue.py
--model_name_or_path bert-base-uncased
--task_name mrpc
--do_train
--do_eval
--per_device_train_batch_size 16
--learning_rate 2e-5
--num_train_epochs 3
--output_dir /tmp/bert-finetuned
--overwrite_output_dir
ステップ7:モデルをテストする
test.pyというテストスクリプトを含むファイルを作成します
from transformers import BertTokenizer, BertForSequenceClassification
import torch
model_path = "/tmp/bert-finetuned"
model = BertForSequenceClassification.from_pretrained(model_path)
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
sentence1 = "This is a great example!"
sentence2 = "This is a demo for code server GPU Container!"
inputs = tokenizer(sentence1, sentence2, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
predicted_class = torch.argmax(logits, dim=1).item()
label_map = {0: "not paraphrase", 1: "paraphrase"}
print(f"Sentence: {sentence1}")
print(f"Sentence: {sentence2}")
print(f"Predicted Class: {predicted_class} ({label_map[predicted_class]})")
ファインチューニングされたモデルをテストするためにtest.pyを実行します
python3 test.py
![]()