Vllm Use Cases Gpt Oss
Giới thiệu
GPT-OSS là series mô hình open-weight mới nhất của OpenAI, được thiết kế cho suy luận mạnh mẽ, tác vụ agentic và các use case lập trình đa dạng. Yêu cầu:
- openai/gpt-oss-20b: cho độ trễ thấp hơn và các use case local hoặc chuyên biệt
- Mô hình nhỏ hơn
- Chỉ cần khoảng 16GB VRAM
- openai/gpt-oss-120b: khuyến nghị cho production, mục đích chung, use case suy luận cao
- Mô hình lớn đầy đủ của chúng tôi
- Tốt nhất với ≥60GB VRAM
- Có thể chạy trên một H100 đơn lẻ hoặc cấu hình multi-GPU
Bước 1: Triển khai container với template vLLM v0.10.1
- Nhấp vào nút Tạo container mới
- Trong phần chọn template, chọn template vLLM mới nhất (v0.10.1).
- Đối với lựa chọn GPU, chỉ cần 1xH100 GPU để phục vụ mô hình
- Giữ nguyên tất cả các cài đặt khác nếu bạn muốn phục vụ openai/gpt-oss-20b. Thay đổi mô hình nếu bạn muốn phục vụ openai/gpt-oss-120b.
- Nhấp Tạo Container để tạo container của bạn.
Chờ container khởi tạo. Quá trình này thường mất khoảng 15 phút để tải mô hình gpt-oss-20b và đến 2 giờ cho mô hình gpt-oss-120b. Bạn có thể theo dõi tiến trình trong Container Logs.
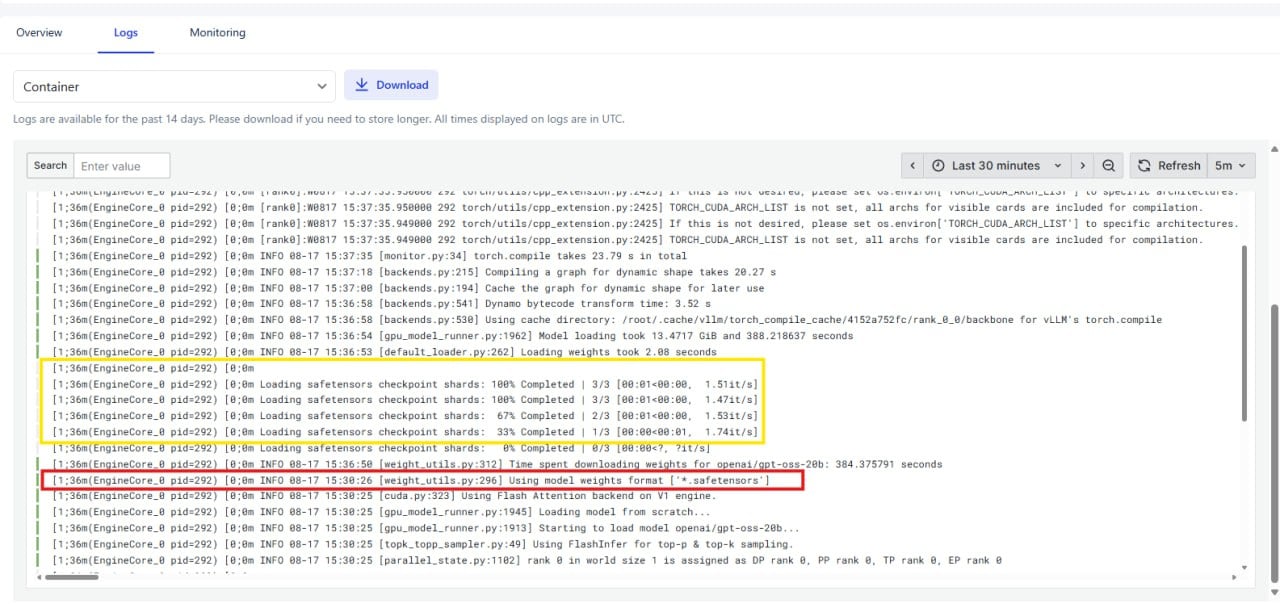
Nếu logs dừng ở dòng tương tự (hộp đỏ trong ảnh chụp màn hình)
Using model weights format [*.safetensors]
Điều này có nghĩa là mô hình vẫn đang tải xuống hoặc khởi tạo, và endpoint chưa sẵn sàng nhận yêu cầu. Mô hình được coi là đã tải đầy đủ và sẵn sàng phục vụ chỉ khi bạn thấy tất cả checkpoint shard đã hoàn thành, như thế này (hộp vàng trong ảnh chụp màn hình)
Loading safetensors checkpoint shards: 100% Completed [3/3]
Điều này cho thấy tất cả các file mô hình đã được tải thành công.
Bước 2: Gửi yêu cầu chạy
Sau khi container đang chạy và mô hình đã tải xuống, bạn có thể gửi yêu cầu chạy để kiểm tra cài đặt.
- Kiểm tra danh sách mô hình khả dụng.
curl -X 'GET' \
'{your endpoint}/v1/models' \ -H 'accept: application/json'.fptcloud.com/v1/models' \
-H 'accept: application/json'
- Kiểm tra mô hình bằng cách đặt một số câu hỏi đơn giản.
curl -X 'POST' \
'{your endpoint}/v1/chat/completions' \88sdgk-8000.serverless.fptcloud.com/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"messages": [
{
"content": "Tell me what is GPT-OSS?",
"role": "user",
"name": "admin"
}
],
"model": " openai/gpt-oss-120b"
}'
!(/img/migrated/information-fill-1-30ad0c7d.png)
Lưu ý: Cả hai mô hình đều được huấn luyện theo định dạng phản hồi harmony và chỉ nên sử dụng với định dạng harmony, vì sẽ không hoạt động đúng nếu dùng cách khác.
Bạn có thể theo dõi hiệu suất, tính khả dụng và mức sử dụng tài nguyên của các dịch vụ container, giúp phát hiện sự cố và tối ưu hóa hoạt động bằng tính năng Monitoring.