テストスイートの選択
モデルをテストするための適切なテストスイートを選択します。
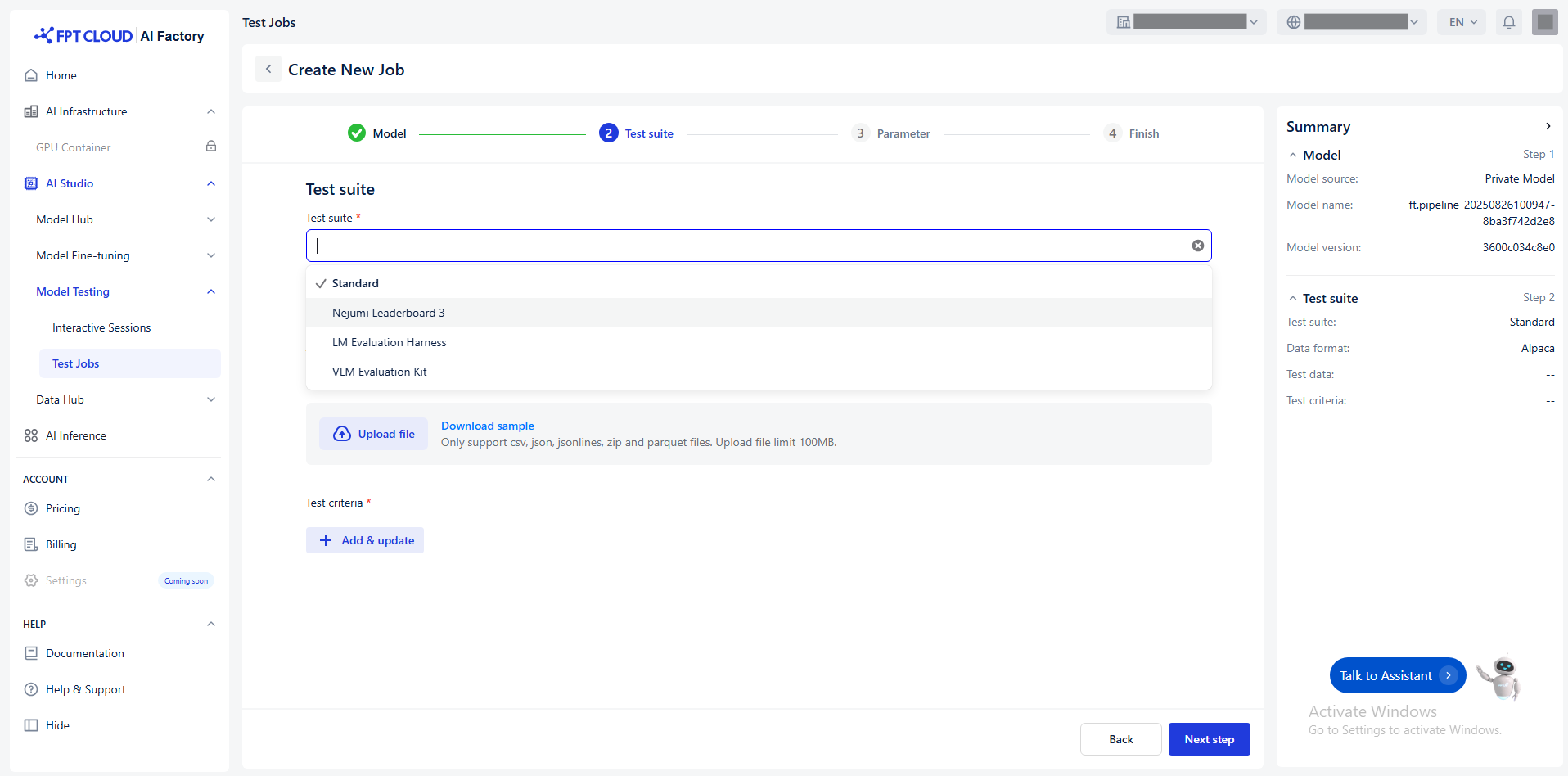
提供しているテストスイートは以下のとおりです:
| テストスイート | 目的 | 最適な用途 | タスク |
|---|---|---|---|
| Standard | 独自のデータセットを使用してモデルを評価します。 | 内部ベンチマーク、ドメイン固有のタスク(金融、医療など) | - Test similarity |
- BLEU
- Fuzzy match
- ROUGE-1
- ROUGE-2
- ROUGE-L
- ROUGE-LSUM |
| Nejumi Leaderboard 3 | 特に日本語タスクにおけるLLMのベンチマーク評価。
参考:Nejumi Leaderboard 3 | 日本語タスクにおけるLLMの比較評価。 | - Jaster
- JBBQ
- JtruthfulQA |
| LM Evaluation Harness | 多くの標準NLPベンチマークにわたって言語モデルを評価する汎用フレームワーク。
参考:LM Evaluation Harness | 英語中心のLLMの評価および研究文献との比較。 | - ARC
- GSM8K
- HellaSwag
- HumanEval
- IFEval
- LAMBADA
- MMLU
- OpenBookQA
- PIQA
- SciQ
- TruthfulQA
- WinoGrande |
| VLM Evaluation Kit | マルチモーダルタスクにおけるVLM(Vision-Language Model)を評価します。
参考:VLMEvalKit | マルチモーダルモデルのテスト。 | - ChartQA
- DocVQA
- InfoVQA
- MTVQA
- OCRBench |