Select Test Suite
Select the appropriate test suite - which tests the model.
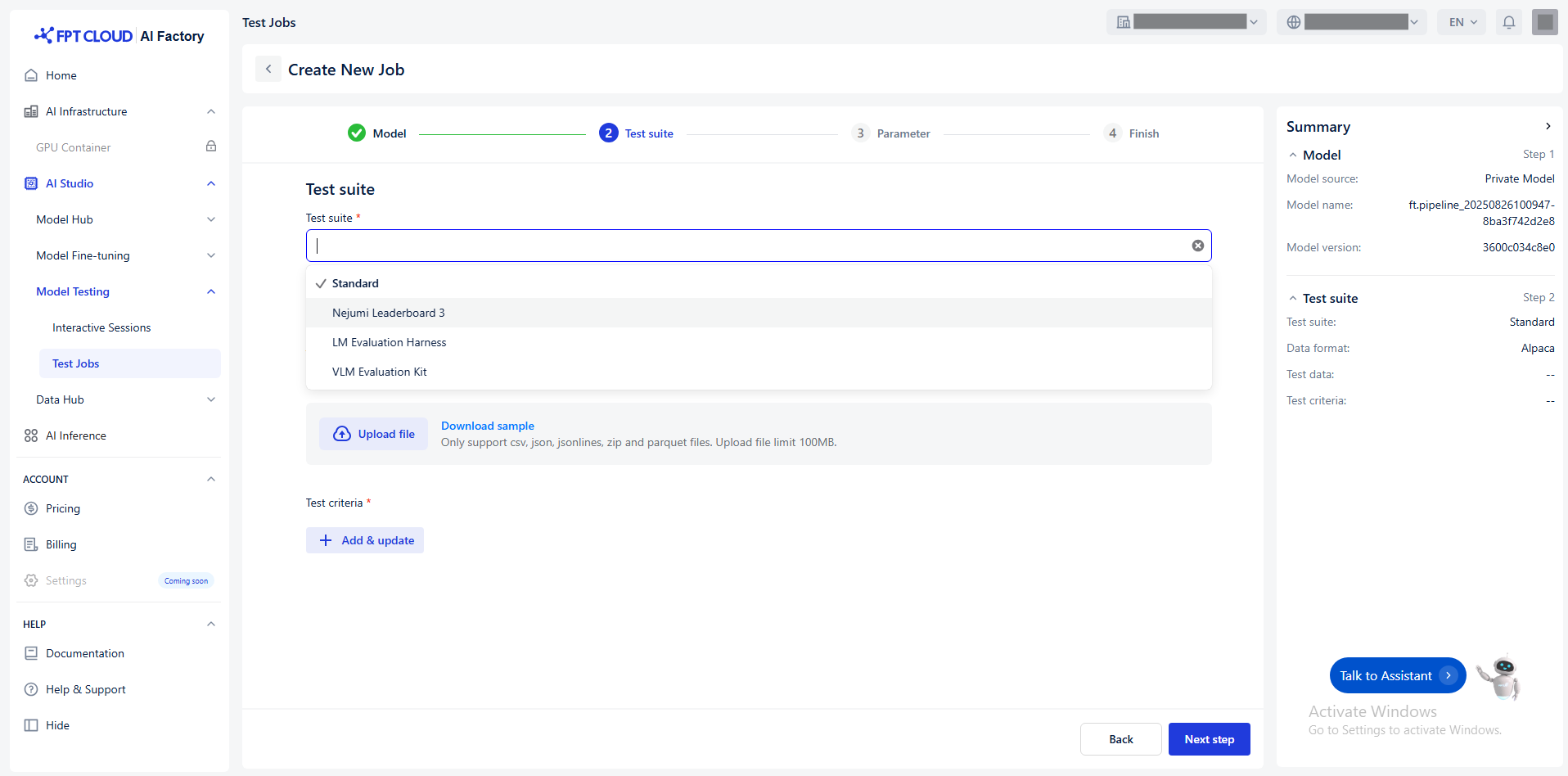
We offer this test suite:
| Test suite | Purpose | Best for | Tasks |
|---|---|---|---|
| Standard | Evaluate models using your own dataset. | Internal benchmarks, domain-specific tasks (e.g., finance, medical, …) | - Test similarity |
- BLEU
- Fuzzy match
- ROUGE-1
- ROUGE-2
- ROUGE-L
- ROUGE-LSUM |
| Nejumi Leaderboard 3 | Benchmark LLMs, especially for Japanese language tasks.
Reference: Nejumi Leaderboard 3 | Comparing LLMs on Japanese language tasks. | - Jaster
- JBBQ
- JtruthfulQA |
| LM Evaluation Harness | General framework to benchmark language models across many standard NLP benchmarks.
Reference: LM Evaluation Harness | Evaluating English-centric LLMs and ensuring comparability with research literature | - ARC
- GSM8K
- HellaSwag
- HumanEval
- IFEval
- LAMBADA
- MMLU
- OpenBookQA
- PIQA
- SciQ
- TruthfulQA
- WinoGrande |
| VLM Evaluation Kit | Evaluate VLMs (Vision-Language Models) on multimodal tasks.
Reference: VLMEvalKit | Testing multimodal models | - ChartQA
- DocVQA
- InfoVQA
- MTVQA
- OCRBench |