Playground
Cách bắt đầu với Playground?
Playground của AI Marketplace cho phép bạn kiểm thử và tương tác với các mô hình AI mà không cần lập trình — bao gồm tạo văn bản, text-to-speech, speech-to-text, các tác vụ thị giác và embedding.
- Trên trang chủ, nhấp Playground trong thanh điều hướng phía trên (giữa Pricing và Support Center).
- Nhấp Get API Key để đến trang My API Key, nơi bạn có thể tạo hoặc quản lý các API key.
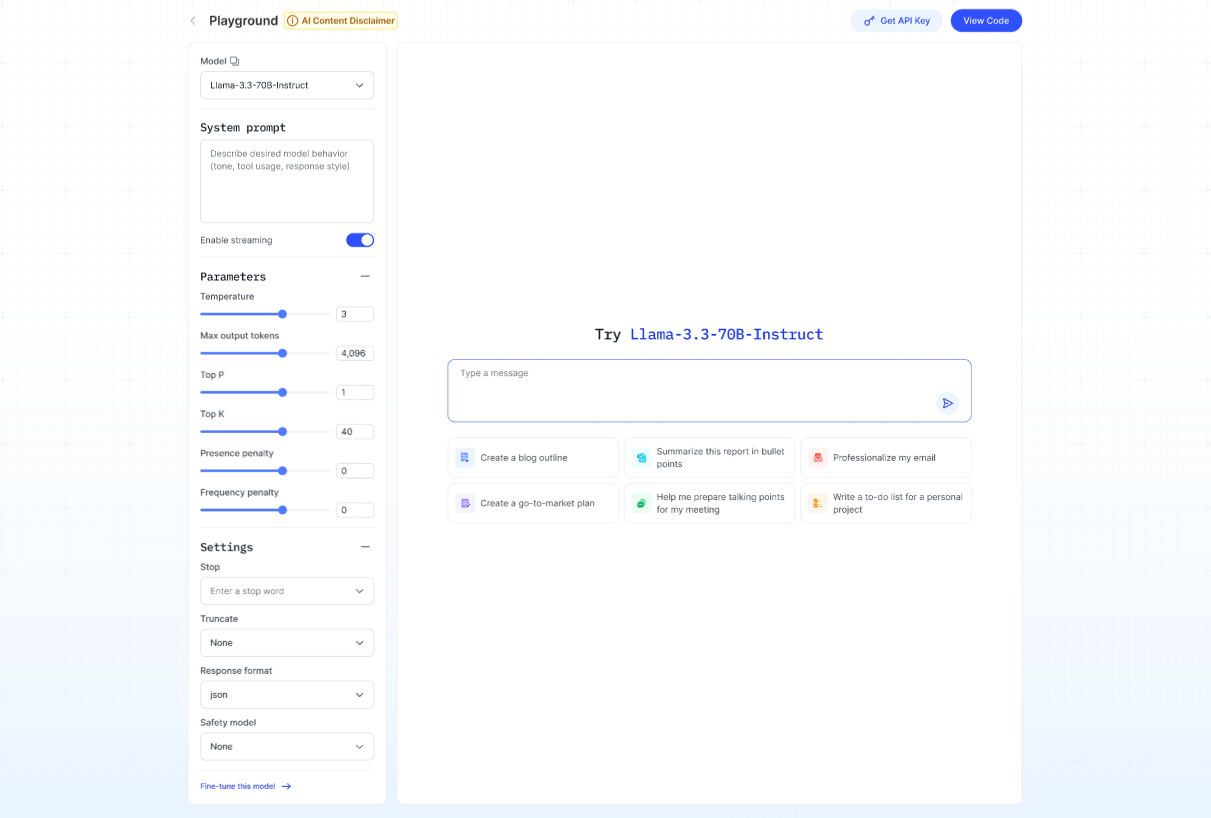
- Nhấp View Code để mở pop-up hiển thị các đoạn code mẫu (có sẵn cho cURL, Python và Node.js) cùng với phản hồi mẫu cho yêu cầu của bạn.
Large Language Model (LLM)
Mô tả: Trợ lý dựa trên văn bản được huấn luyện trên lượng lớn thông tin (sách, trang web, bài viết, hội thoại). Mô hình có thể hiểu yêu cầu của bạn và phản hồi bằng văn bản tự nhiên, giống người thật.
Các mẫu quick action có sẵn:
- Tạo outline cho blog
- Tạo kế hoạch go-to-market
- Tóm tắt báo cáo này dưới dạng bullet point
- Giúp tôi chuẩn bị các điểm trình bày cho cuộc họp
- Chuyên nghiệp hóa email của tôi
- Viết danh sách công việc cho dự án cá nhân
Các bước thực hiện:
- Nhấp vào tác vụ phù hợp nhất với nhu cầu của bạn. Hệ thống sẽ tự động chuẩn bị phản hồi dựa trên đầu vào của bạn.
- Nhập câu hỏi, chủ đề hoặc yêu cầu cụ thể liên quan đến tác vụ đã chọn vào ô văn bản.
- Nhấp Send — kết quả sẽ hiện ra ở bên phải.
Cài đặt nâng cao (bảng bên trái):
- System prompt — thiết lập phong cách/hành vi của trợ lý.
- Temperature, Max output tokens, Top P, Top K, Penalties — tinh chỉnh độ sáng tạo, độ dài và độ ngẫu nhiên.
Mô hình Text to Speech (TTS)
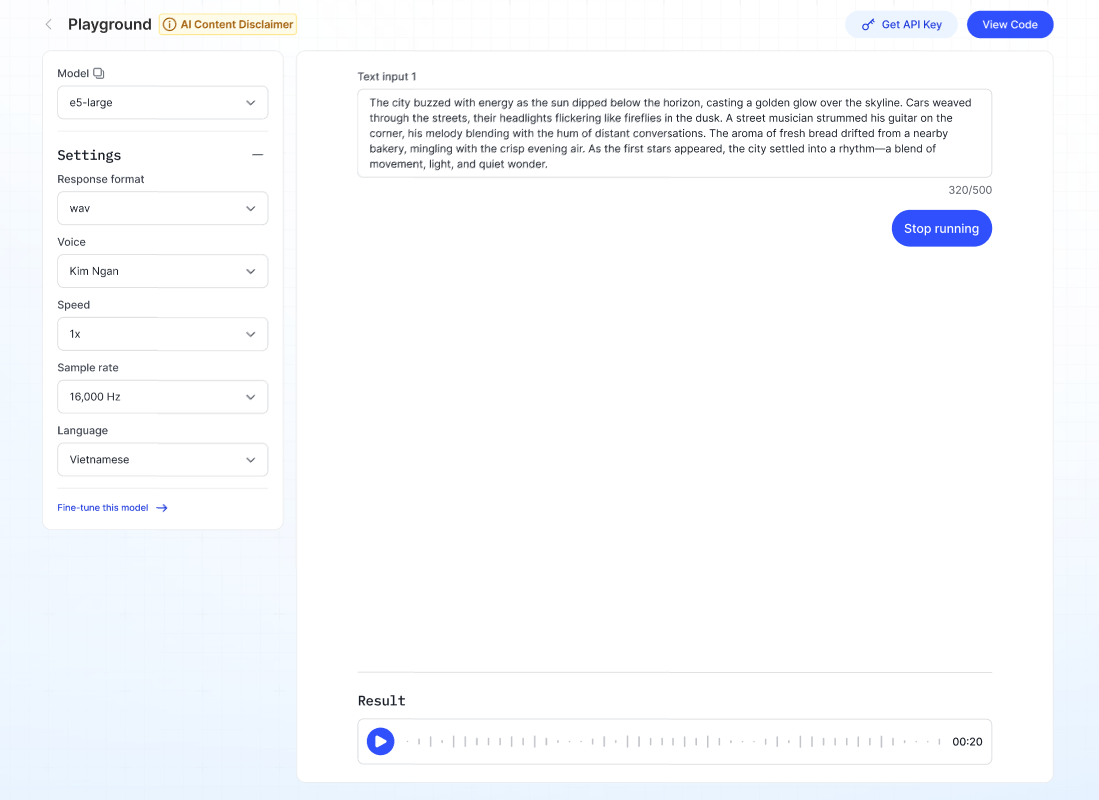
Mô tả: Chuyển đổi văn bản thành giọng nói.
Các bước thực hiện:
- Chọn loại giọng trong dropdown Voice.
- Chọn tốc độ giọng trong dropdown Speed.
- Chọn ngôn ngữ trong dropdown Language.
- Nhập tối đa 500 ký tự vào ô Text.
- Nhấp Run — hệ thống sẽ tạo file âm thanh, có thể phát hoặc tải xuống.
Mô hình Speech to Text (STT)
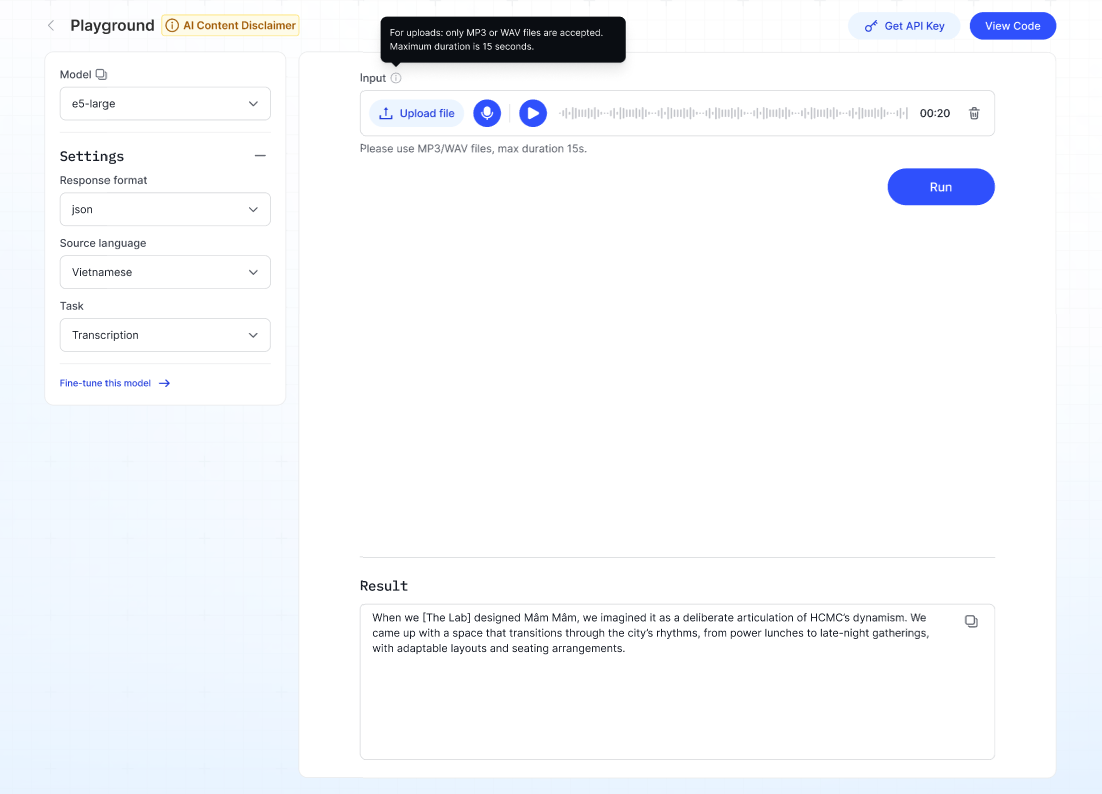
Mô tả: Chuyển đổi giọng nói thành văn bản.
Các bước thực hiện:
- Chọn Model từ dropdown.
- Chọn Response format (ví dụ: json hoặc text).
- Đặt Source language.
- Chọn Task:
- Transcription — chuyển đổi giọng nói thành văn bản.
- Translation — chuyển đổi giọng nói thành văn bản bằng ngôn ngữ khác.
- Tải lên hoặc ghi âm (các định dạng hỗ trợ: MP3/WAV, độ dài tối đa 15s).
- Nhấp Run — văn bản được phiên âm hoặc dịch sẽ xuất hiện trong phần Result.
Vision Language Model (VLM)
Mô tả: Trợ lý kết hợp thị giác máy tính (hiểu hình ảnh) và xử lý ngôn ngữ tự nhiên (hiểu văn bản) để nhận thức thế giới theo cách gần với con người hơn.
Các bước thực hiện:
- Tải lên ảnh của bạn (JPEG, PNG, JPG, tối đa 2 file, 20 MB mỗi file).
- Đặt câu hỏi về ảnh trong ô văn bản.
- Nhấp Run — mô hình sẽ phản hồi dựa trên nội dung ảnh.
Mô hình Embedding
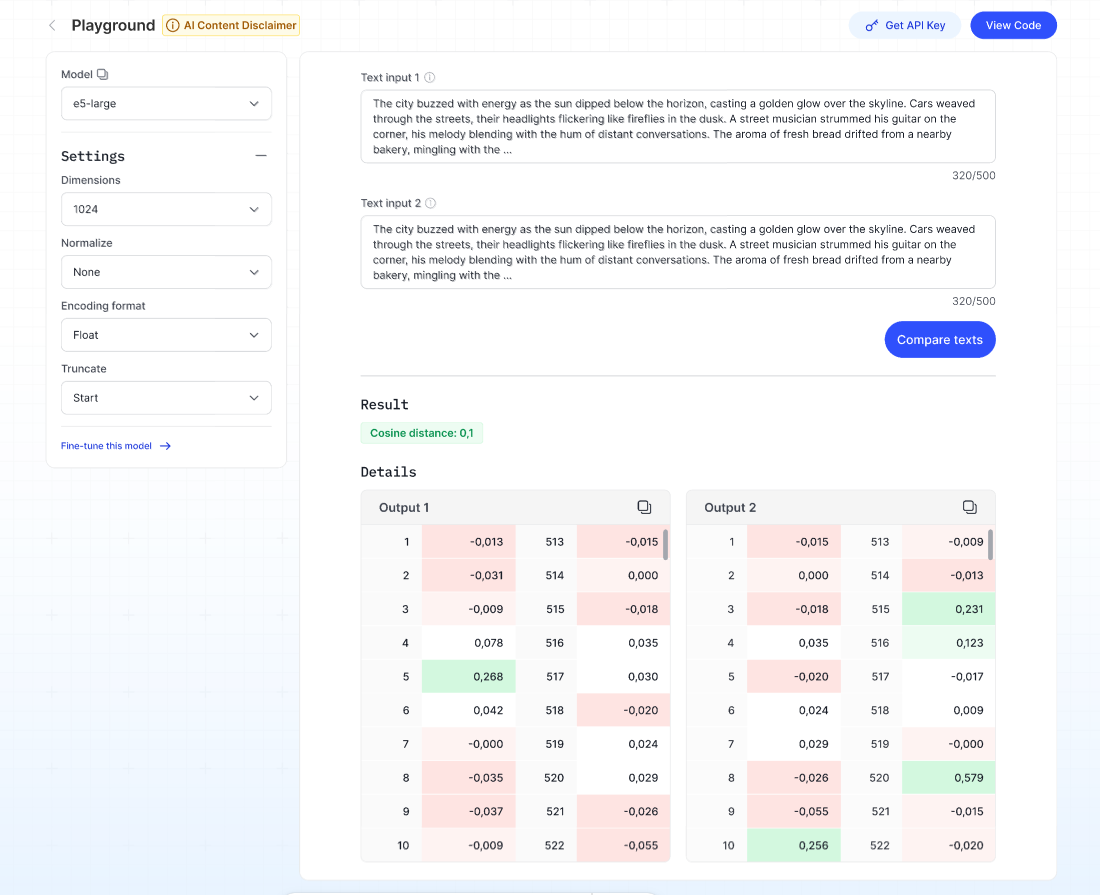
Mô tả: Mô hình embedding là các mạng neural dựa trên transformer, chuyển đổi các đoạn tài liệu (đoạn văn bản) thành biểu diễn số hay vector. Các vector này nắm bắt ý nghĩa ngữ nghĩa của văn bản và được dùng cho các tác vụ như tìm kiếm, gợi ý và so sánh độ tương đồng.
Các bước thực hiện:
- Chọn loại đầu vào bạn muốn kiểm thử trong dropdown Input type.
- Chọn định dạng đầu ra mong muốn cho embedding trong dropdown Encoding format.
- Chọn cách xử lý đầu vào vượt quá giới hạn token trong dropdown Truncate.
- Nhập tối đa 500 ký tự vào ô Text.
- Nhấp Run — hệ thống sẽ hiển thị embedding vector (biểu diễn số) trong phần Result.
Tính năng Guardrail sẽ sớm ra mắt để tăng cường an toàn nội dung.
Cách sử dụng các điều khiển bổ sung trong Playground?
- System prompt — hướng dẫn hành vi và phong cách của mô hình.
- Enable streaming — hiển thị kết quả một phần trong khi đang tạo.
- Stop sequences — dừng phản hồi của mô hình tại các từ hoặc cụm từ cụ thể.
- Fine-tune this model — liên kết để bắt đầu tùy chỉnh mô hình cho trường hợp sử dụng của bạn.