Select Dataset Format
Định dạng dataset phụ thuộc vào trainer được chọn.
| Trainer | Định dạng dữ liệu hỗ trợ | Định dạng file hỗ trợ | Kích thước file hỗ trợ |
|---|---|---|---|
| SFT | Alpaca | CSV, JSON, JSONLINES, ZIP, PARQUET | Giới hạn 100MB |
| SFT | ShareGPT | JSON, JSONLINES, ZIP, PARQUET | Giới hạn 100MB |
| SFT | ShareGPT_Image | ZIP, PARQUET | Giới hạn 100MB |
| DPO | ShareGPT | JSON, JSONLINES, ZIP, PARQUET | Giới hạn 100MB |
| Pre-training | Corpus | TXT, JSON, JSONLINES, ZIP, PARQUET | Giới hạn 100MB |
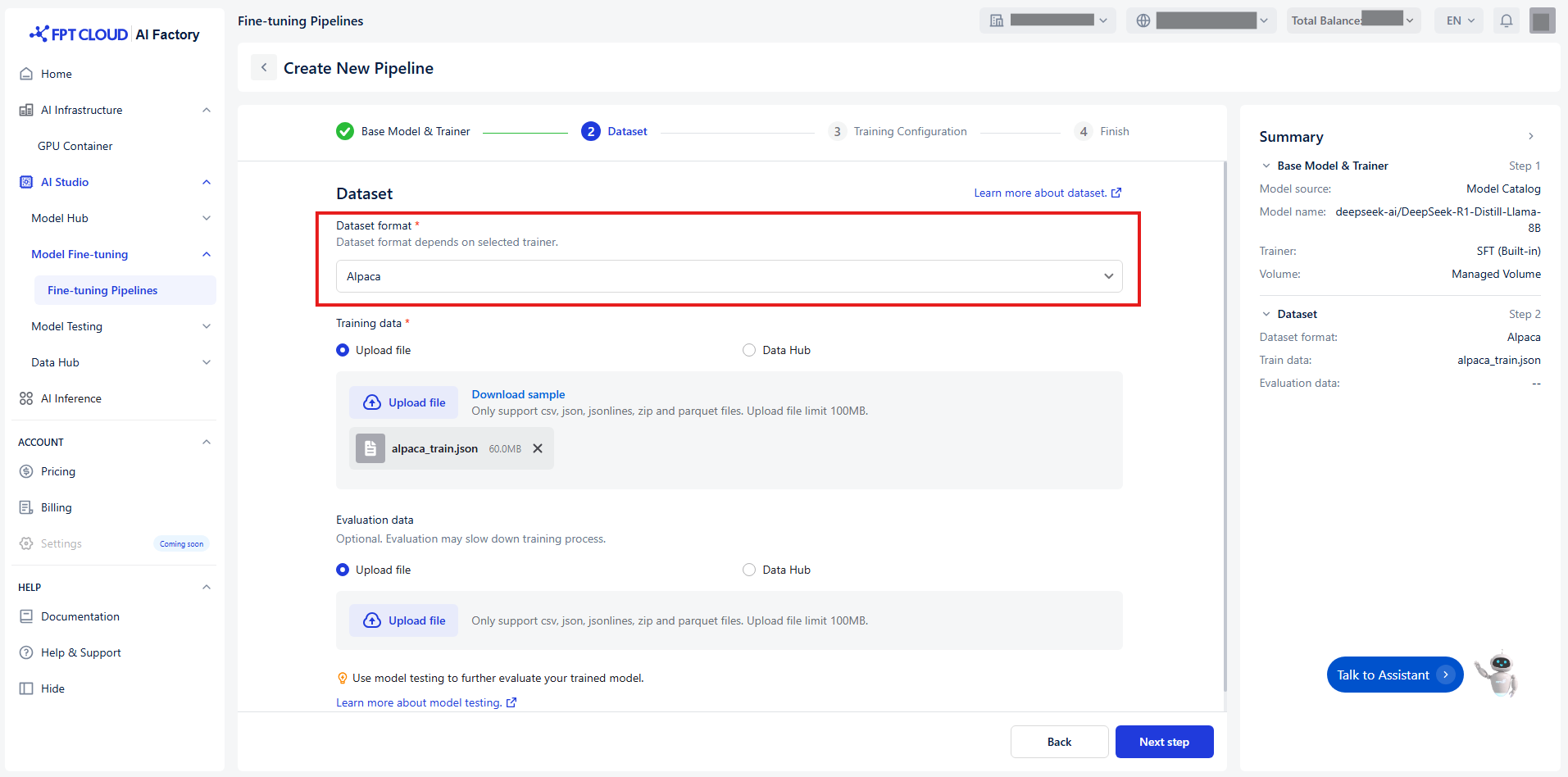
Hiện tại chúng tôi hỗ trợ các định dạng dữ liệu cho fine-tuning bao gồm:
a/ Alpaca
Alpaca sử dụng cấu trúc rất đơn giản để fine-tuning model theo định dạng Instruction-following với các cặp input, output cho các tác vụ supervised fine-tuning. Cấu trúc cơ bản bao gồm:
- Instruction: Chuỗi chứa tác vụ hoặc yêu cầu cụ thể mà model cần thực hiện.
- Input: Chuỗi chứa thông tin mà model cần xử lý để thực hiện tác vụ.
- Output: Chuỗi đại diện cho kết quả model cần trả về, được tạo ra từ việc xử lý instruction và input.
Cấu trúc chi tiết:
[
{
"instruction": "string",
"input": "string",
"output": "string"
}
]
Mẫu: https://github.com/fpt-corp/ai-studio-samples/tree/main/sample-datasets/alpaca
Định dạng file hỗ trợ: .csv, .json, .jsonlines, .zip, .parquet
b/ ShareGPT
b.1/ Trainer = SFT
ShareGPT được thiết kế để đại diện cho các cuộc hội thoại nhiều lượt giữa người dùng và trợ lý AI. Nó thường được dùng khi training hoặc fine-tuning các model cho hệ thống hội thoại hoặc chatbot cần xử lý ngữ cảnh qua nhiều lượt.
Mỗi mẫu dữ liệu bao gồm một mảng conversations, trong đó mỗi lượt chat gồm:
- from: Người đang nói — thường là
"human"hoặc"gpt". - value: Nội dung tin nhắn thực tế từ người nói đó.
Cấu trúc chi tiết:
[
{
"conversations": [
{
"from": "string",
"value": "string"
}
]
}
]
Mẫu: https://github.com/fpt-corp/ai-studio-samples/tree/main/sample-datasets/sharegpt
Định dạng file hỗ trợ: .json, .jsonlines, .zip, .parquet
b.2/ Trainer = DPO
ShareGPT_DPO là dataset gồm các cuộc hội thoại (prompt + response) được thu thập từ ShareGPT, cùng với các cặp response đã được con người xếp hạng dựa trên chất lượng. Được dùng để:
- Training các language model để phản hồi theo cách phù hợp với sở thích của con người.
- Tối ưu hóa chất lượng response sử dụng phương pháp DPO (Direct Preference Optimization).
Cấu trúc chi tiết:
[
{
"conversations": [
{
"from": "string",
"value": "string"
}
],
"chosen": {
"from": "string",
"value": "string"
},
"rejected": {
"from": "string",
"value": "string"
}
}
]
Mẫu: https://github.com/fpt-corp/ai-studio-samples/tree/main/sample-datasets/sharegpt-dpo
Định dạng file hỗ trợ: .json, .jsonlines, .zip, .parquet
c/ ShareGPT_Image
ShareGPT_Image là phần mở rộng của định dạng chat nhiều lượt ShareGPT, được thiết kế đặc biệt cho training đa phương thức — tức là training các model xử lý cả văn bản và hình ảnh trong các cuộc hội thoại.
Cấu trúc bao gồm:
- Danh sách các lượt chat trong
"message"(giống ShareGPT). - Trường
"image"hoặc"image_path"trỏ đến hình ảnh được sử dụng trong cuộc hội thoại (định dạng png, jpg, jpeg).
Lưu ý:
- Phải bao gồm token
imagetrong nội dung chat nơi hình ảnh sẽ xuất hiện. - Nếu có nhiều hình ảnh: đường dẫn hình ảnh phải được định nghĩa trong mảng
images; vị trí của hình ảnh trong luồng chat được chỉ định bởi các tokenimage; số lượng tokenimagephải khớp với số mục trong mảngimages.
Định dạng file hỗ trợ: .zip, .parquet
Mẫu: https://github.com/fpt-corp/ai-studio-samples/tree/main/sample-datasets/sharegpt-image
d/ Corpus
Corpus là tập hợp văn bản dùng để training hoặc fine-tuning language model. Mỗi điểm dữ liệu trong corpus bao gồm trường "text" với một chuỗi văn bản. Định dạng này thường được dùng khi bạn không cần phân biệt giữa instruction và output, mà chỉ muốn cung cấp dữ liệu văn bản thô cho model học.
Cấu trúc chi tiết:
[
{
"text": "string"
}
]
Mẫu: https://github.com/fpt-corp/ai-studio-samples/tree/main/sample-datasets/corpus
Định dạng file hỗ trợ: .txt, .json, .jsonlines, .zip, .parquet