Select Trainer
Chọn trainer phù hợp — trainer sẽ hướng dẫn model bạn chọn trong quá trình training.
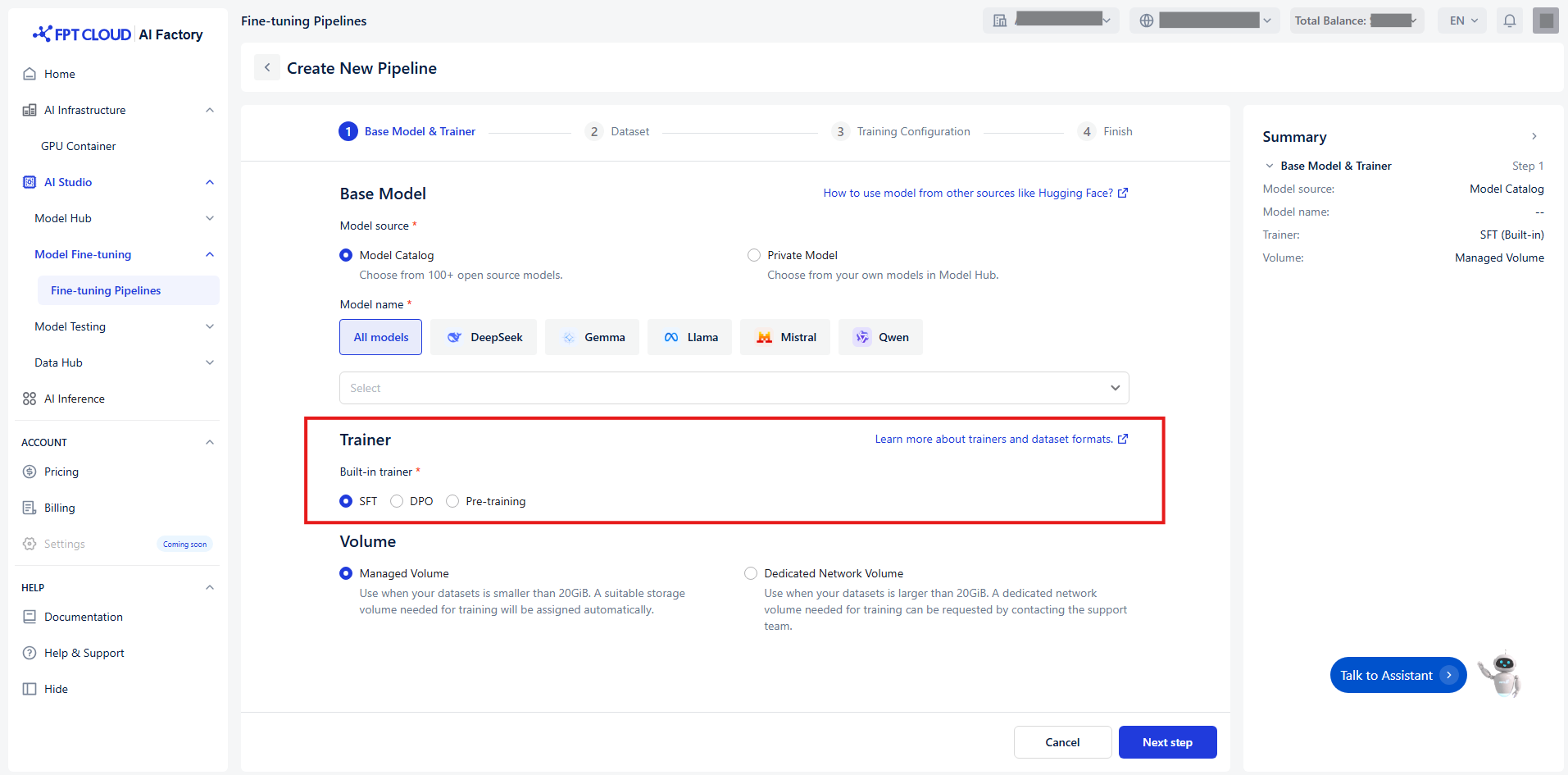
Chúng tôi cung cấp ba trainer để tối ưu hóa model của bạn:
| Trainer | Định nghĩa | Cách hoạt động | Phù hợp nhất cho |
|---|---|---|---|
| SFT (Supervised fine-tuning) | Kỹ thuật nền tảng huấn luyện model trên các cặp input-output, dạy model tạo ra các phản hồi mong muốn cho các input cụ thể. | - Cung cấp các ví dụ về phản hồi đúng cho các prompt để hướng dẫn hành vi của model. - Thường sử dụng các phản hồi "ground truth" do con người tạo ra. | - Phân loại - Dịch thuật tinh tế - Tạo nội dung theo định dạng cụ thể - Sửa lỗi instruction-following |
| DPO (Direct preference optimization) | Huấn luyện model ưu tiên một số loại phản hồi hơn các loại khác bằng cách học từ phản hồi so sánh, không cần reward model riêng biệt. | - Cung cấp cả phản hồi đúng và sai cho một prompt. - Chỉ ra phản hồi đúng để giúp model hoạt động tốt hơn. | - Tóm tắt văn bản, tập trung vào đúng nội dung - Tạo tin nhắn chat với giọng điệu và phong cách phù hợp |
| Pre-training | Giai đoạn training ban đầu sử dụng dữ liệu không được gán nhãn quy mô lớn để hiểu ngôn ngữ. | - Tiếp xúc model với lượng lớn dữ liệu văn bản để học ngữ pháp, sự kiện, các mẫu suy luận và kiến thức thế giới. - Không yêu cầu ví dụ có nhãn. | - Xây dựng hiểu biết ngôn ngữ nền tảng - Chuẩn bị model cho các tác vụ fine-tuning downstream |