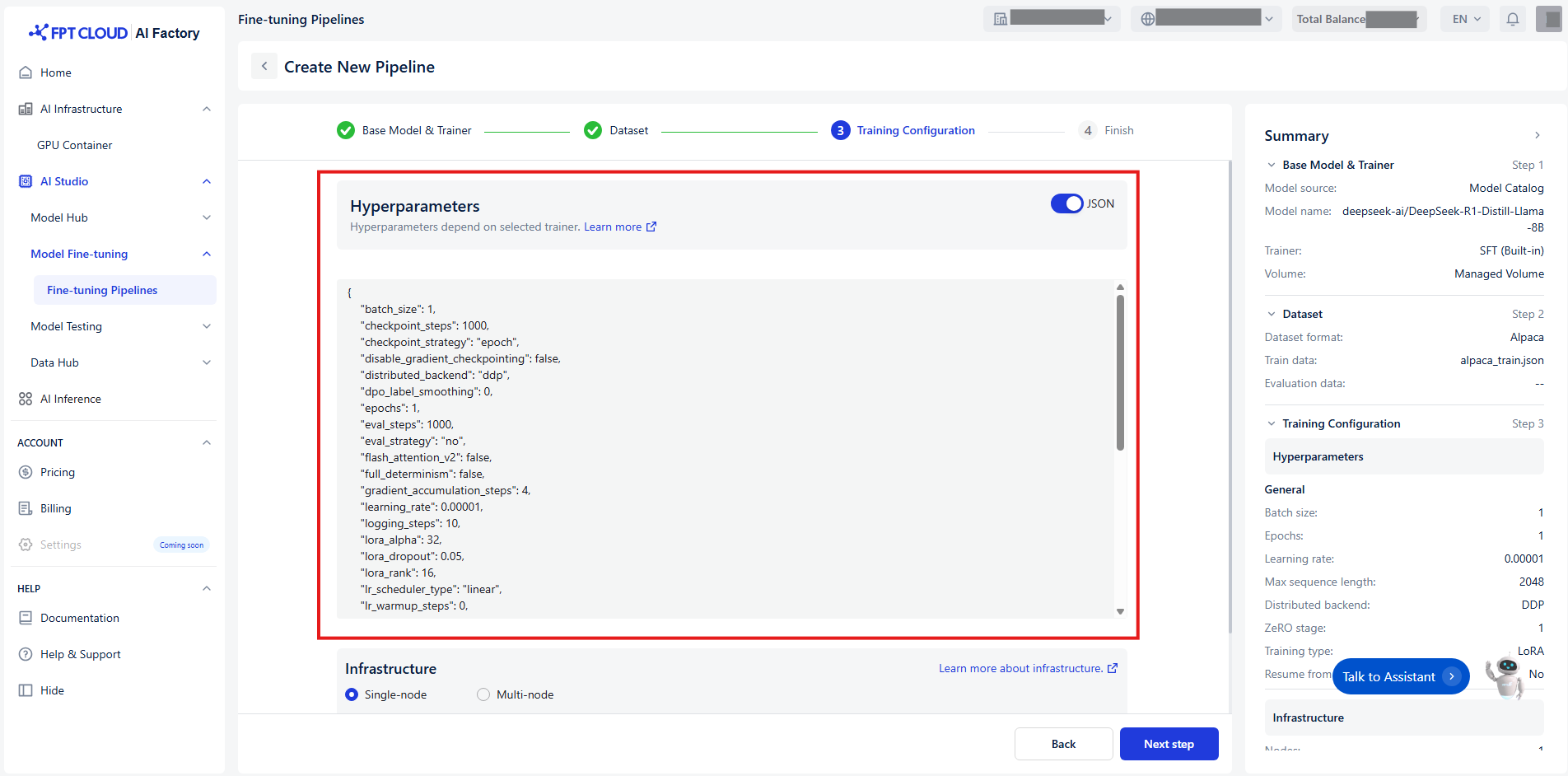
Set Up Hyperparameters
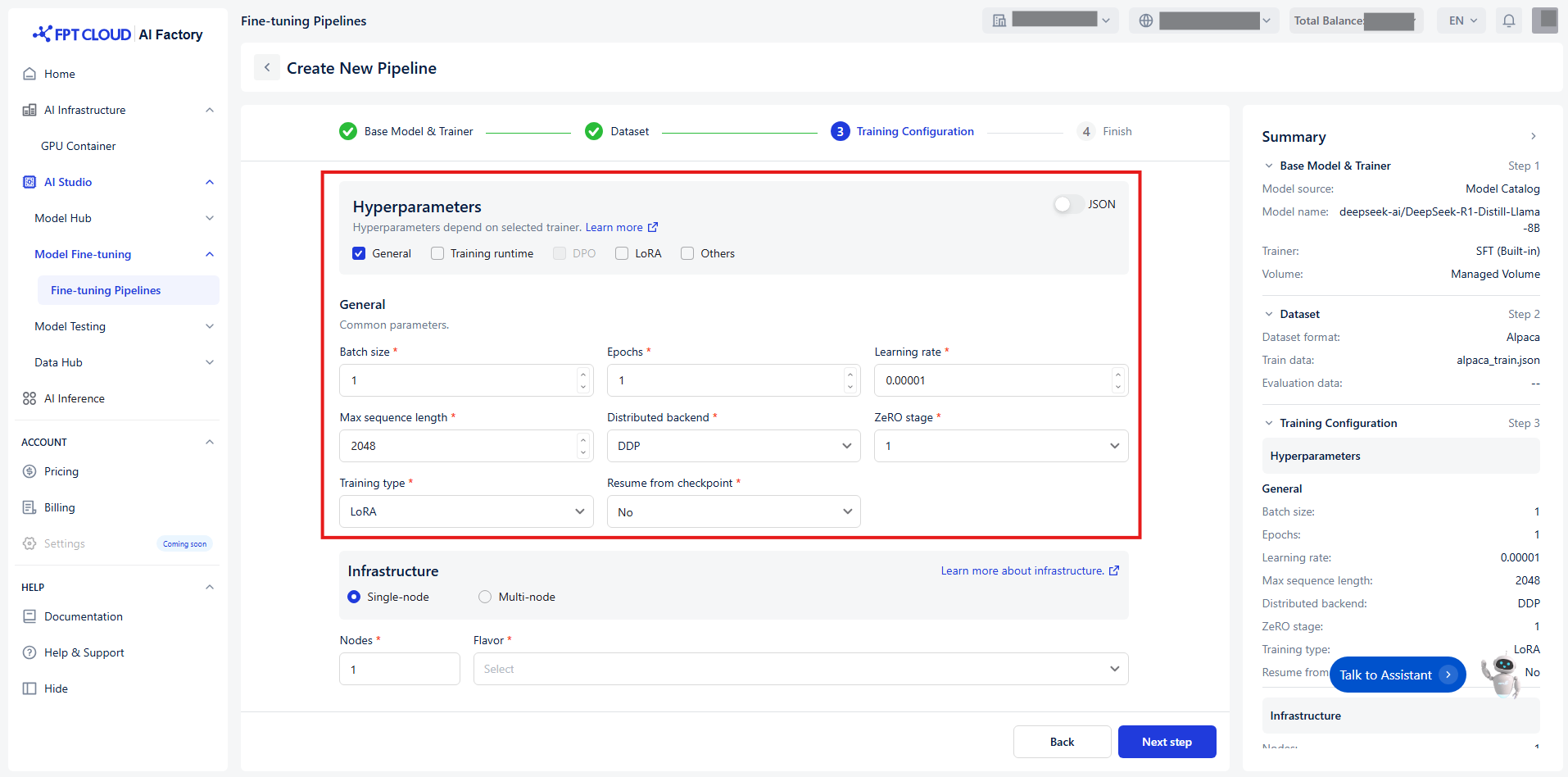
Hyperparameter kiểm soát cách trọng số của model được cập nhật trong quá trình training. Để dễ dàng cấu hình hơn, chúng tôi phân loại hyperparameter thành 5 nhóm riêng biệt dựa trên chức năng và mức độ liên quan:
Nhóm 1 - General
Các cài đặt cốt lõi của quá trình training.
| Tên | Mô tả | Kiểu | Giá trị hỗ trợ |
|---|---|---|---|
| Batch size | Số ví dụ model xử lý trong một lượt forward và backward pass trước khi cập nhật trọng số. Batch lớn làm chậm training nhưng có thể tạo ra kết quả ổn định hơn. Trong trường hợp distributed training, đây là batch size trên mỗi thiết bị. | Int | [1, +∞) |
| Epochs | Một epoch là một lượt duyệt qua toàn bộ dữ liệu training trong quá trình training model. Bạn thường chạy nhiều epoch để model có thể tinh chỉnh lặp đi lặp lại các trọng số. | Int | [1, +∞) |
| Learning rate | Điều chỉnh kích thước thay đổi đối với các tham số đã học của model. | Float | (0, 1) |
| Max sequence length | Độ dài input tối đa, các chuỗi dài hơn sẽ bị cắt bớt về giá trị này. | Int | [1, +∞) |
| Distributed backend | Backend sử dụng cho distributed training. | Enum[string] | DDP, DeepSpeed |
| ZeRO stage | Giai đoạn áp dụng thuật toán DeepSpeed ZeRO. Chỉ áp dụng khi Distributed backend = DeepSpeed. | Enum[int] | 1, 2, 3 |
| Training type | Chế độ tham số nào sẽ sử dụng. | Enum[string] | Full, LoRA |
| Resume from checkpoint | Đường dẫn tương đối của checkpoint mà training engine sẽ tiếp tục từ đó. | Union[bool, string] | No, Last checkpoint, Path/to/checkpoint |
Nhóm 2 - Training runtime
Tối ưu hóa hiệu quả và hiệu suất của quá trình training.
| Tên | Mô tả | Kiểu | Giá trị hỗ trợ |
|---|---|---|---|
| Gradient accumulation steps | Số bước cập nhật để tích lũy gradient trước khi thực hiện backward/update pass. | Int | [1, +∞) |
| Mixed precision | Loại mixed precision sử dụng. | Enum[string] | Bf16, Fp16, None |
| Quantization bit | Số bit để lượng tử hóa model sử dụng quantization on-the-fly. Hiện chỉ áp dụng khi Training type = LoRA. | Enum[string] | None |
| Optimizer | Optimizer sử dụng cho training. | Enum[string] | Adamw, Sgd |
| Weight decay | Weight decay áp dụng cho optimizer. | Float | [0, +∞) |
| Max gradient norm | Norm tối đa để gradient clipping. | Float | [0, +∞) |
| Disable gradient checkpointing | Có vô hiệu hóa gradient checkpointing hay không. | Bool | True, False |
| Flash attention v2 | Có sử dụng flash attention phiên bản 2 hay không. Hiện chỉ hỗ trợ false. | Bool | False |
| LR warmup steps | Số bước sử dụng cho linear warmup từ 0 đến Learning rate. | Int | [0, +∞) |
| LR warmup ratio | Tỷ lệ tổng số bước training sử dụng cho linear warmup. | Float | [0, 1) |
| LR scheduler | Learning rate scheduler sử dụng. | Enum[string] | Linear, Cosine, Constant |
| Full determinism | Đảm bảo kết quả có thể tái tạo trong distributed training. Quan trọng: điều này sẽ ảnh hưởng tiêu cực đến hiệu suất, vì vậy chỉ sử dụng để debug. Nếu True, cài đặt Seed sẽ không có hiệu lực. | Bool | True, False |
| Seed | Random seed để đảm bảo tính tái tạo. | Int | [0, +∞) |
Nhóm 3 - DPO
Bật nhóm này khi sử dụng trainer = DPO.
| Tên | Mô tả | Kiểu | Giá trị hỗ trợ |
|---|---|---|---|
| DPO label smoothing | Tham số DPO label smoothing mạnh mẽ trong DPO nên nằm trong khoảng 0 đến 0.5. | Float | [0, 0.5] |
| Preference beta | Tham số beta trong preference loss. | Float | [0, 1] |
| Preference fine-tuning mix | Hệ số SFT loss trong DPO training. | Float | [0, 10] |
| Preference loss | Loại DPO loss sử dụng. | Enum[string] | Sigmoid, Hinge, Ipo, Kto pair, Orpo, Simpo |
| SimPO gamma | Target reward margin trong SimPO loss. Chỉ sử dụng khi áp dụng được. | Float | (0, +∞) |
Nhóm 4 - LoRA
Bật nhóm này khi sử dụng Training type = LoRA.
| Tên | Mô tả | Kiểu | Giá trị hỗ trợ |
|---|---|---|---|
| Merge adapter | Có hợp nhất LoRA adapter vào base model để cung cấp model cuối cùng hay không. Nếu không, chỉ LoRA adapter sẽ được lưu sau khi training xong. | Bool | True, False |
| LoRA alpha | Tham số alpha cho LoRA. | Int | [1, +∞) |
| LoRA dropout | Tỷ lệ dropout cho LoRA. | Float | [0, 1] |
| LoRA rank | Rank của các ma trận LoRA. | Int | [1, +∞) |
| Target modules | Các module mục tiêu cho quantization hoặc fine-tuning. | String | All linear |
Nhóm 5 - Others
Kiểm soát cách theo dõi và lưu tiến trình fine-tuning.
| Tên | Mô tả | Kiểu | Giá trị hỗ trợ |
|---|---|---|---|
| Checkpoint strategy | Chiến lược lưu checkpoint áp dụng trong training. "best" chỉ áp dụng khi Evaluation strategy không phải "no". | Enum[string] | No, Epoch, Steps |
| Checkpoint steps | Số bước training giữa hai lần lưu checkpoint nếu Checkpoint strategy = step. | Int | [1, +∞) |
| Evaluation strategy | Chiến lược đánh giá áp dụng trong training. | Enum[string] | No, Epoch, Steps |
| Evaluation steps | Số bước cập nhật giữa hai lần đánh giá nếu Evaluation strategy = steps. Mặc định bằng giá trị Logging steps nếu không được đặt. | Int | [1, +∞) |
| No. of checkpoints | Nếu được truyền giá trị, sẽ giới hạn tổng số checkpoint. | Int | [1, +∞) |
| Save best checkpoint | Có theo dõi và giữ checkpoint tốt nhất hay không. Hiện chỉ hỗ trợ False. | Bool | False |
| Logging steps | Số bước giữa các sự kiện ghi log bao gồm stdout logs và các điểm dữ liệu MLflow. Logging steps = -1 nghĩa là ghi log trên mỗi bước. | Int | [0, +∞) |
Hoặc bạn có thể thiết lập hyperparameter nhanh chóng bằng cách chuyển sang toggle JSON: