Load fine-tuned model and tokenizer
Finetune BERT on GLUE MRPC using Code Server
This guide will walk you through fine-tuning a pre-trained BERT model on the GLUE MRPC task using a GPU-enabled Code Server container.
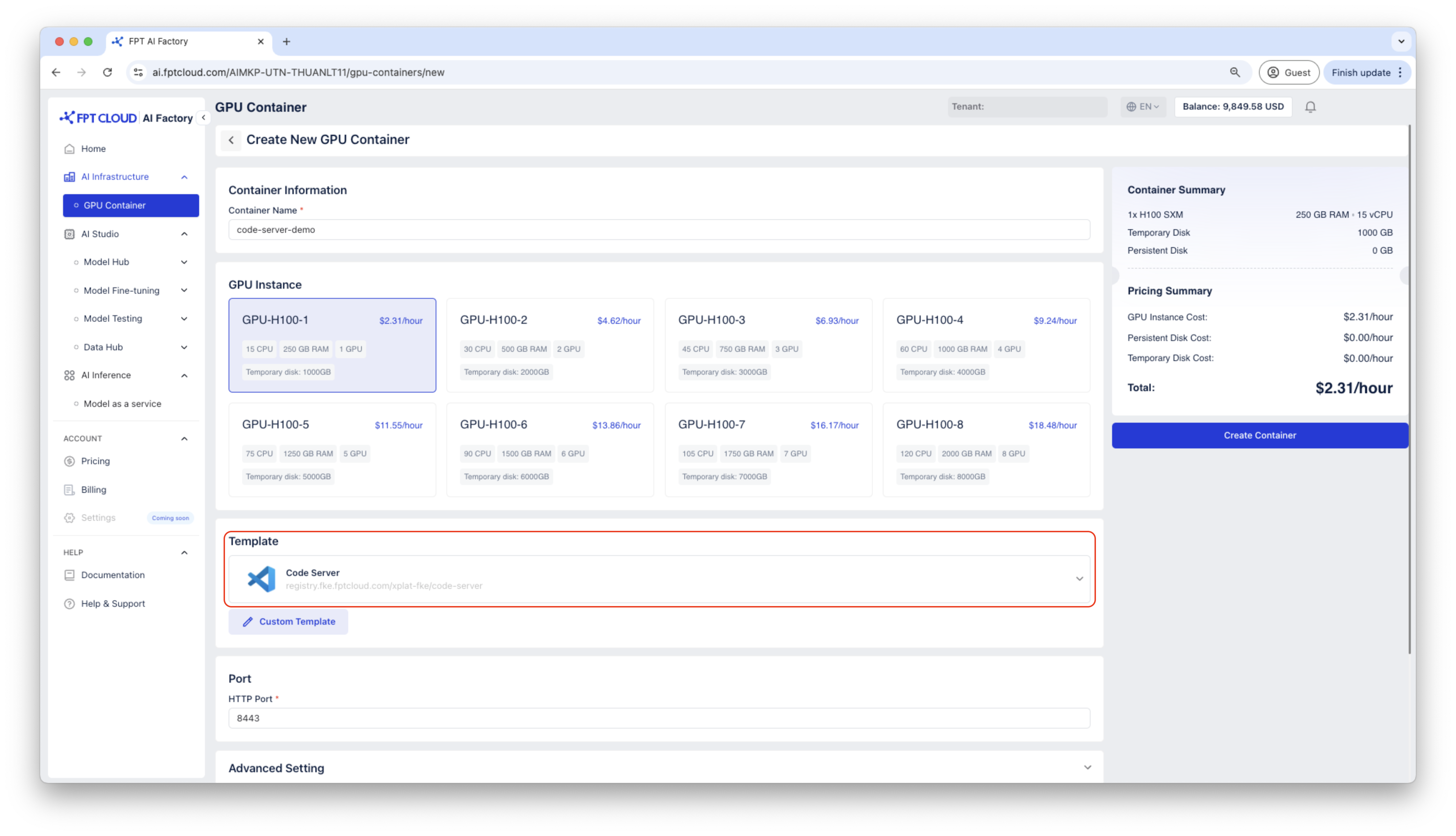
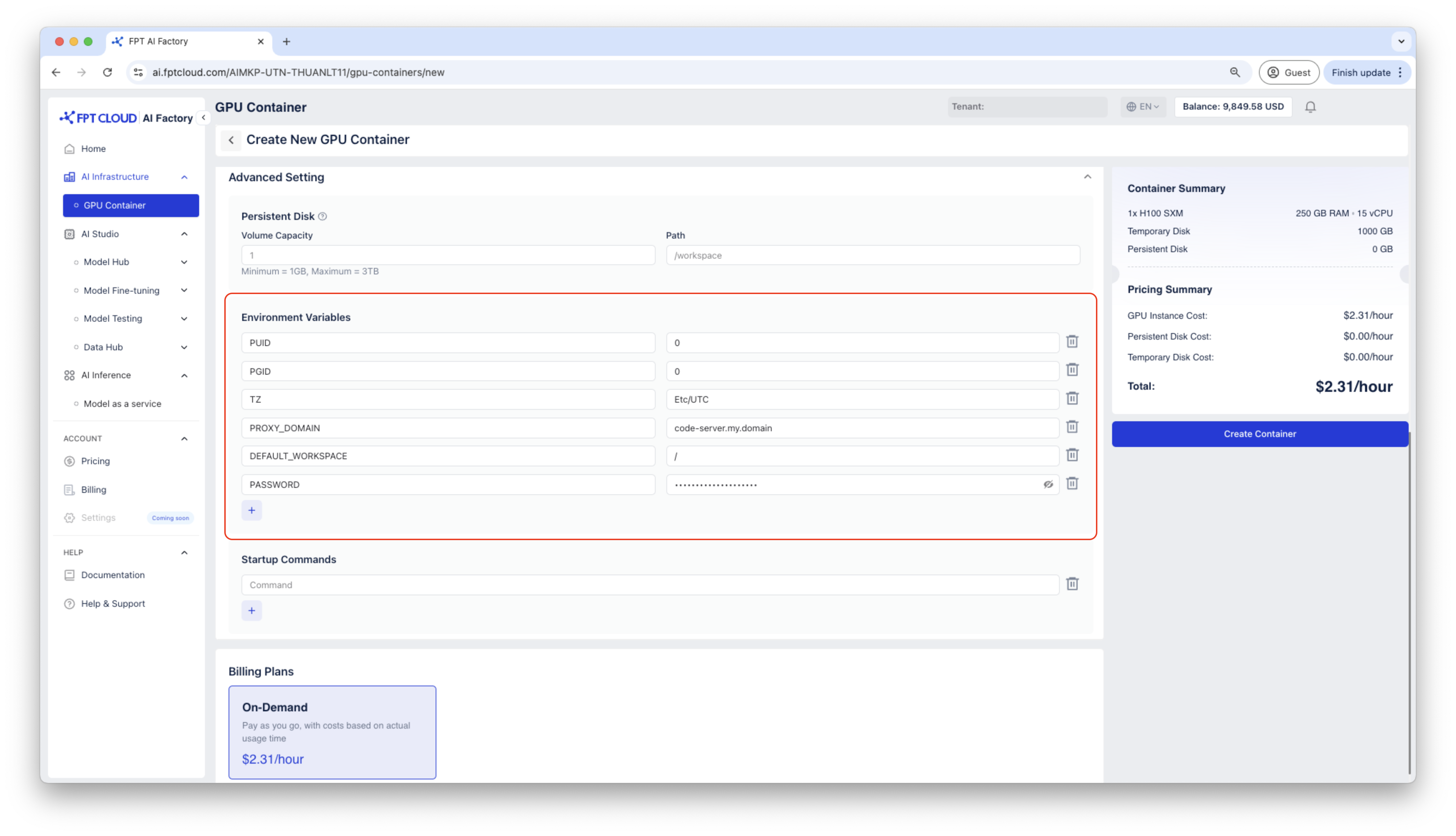
Step 1: Create a GPU Container
Create a container using Code Server template.
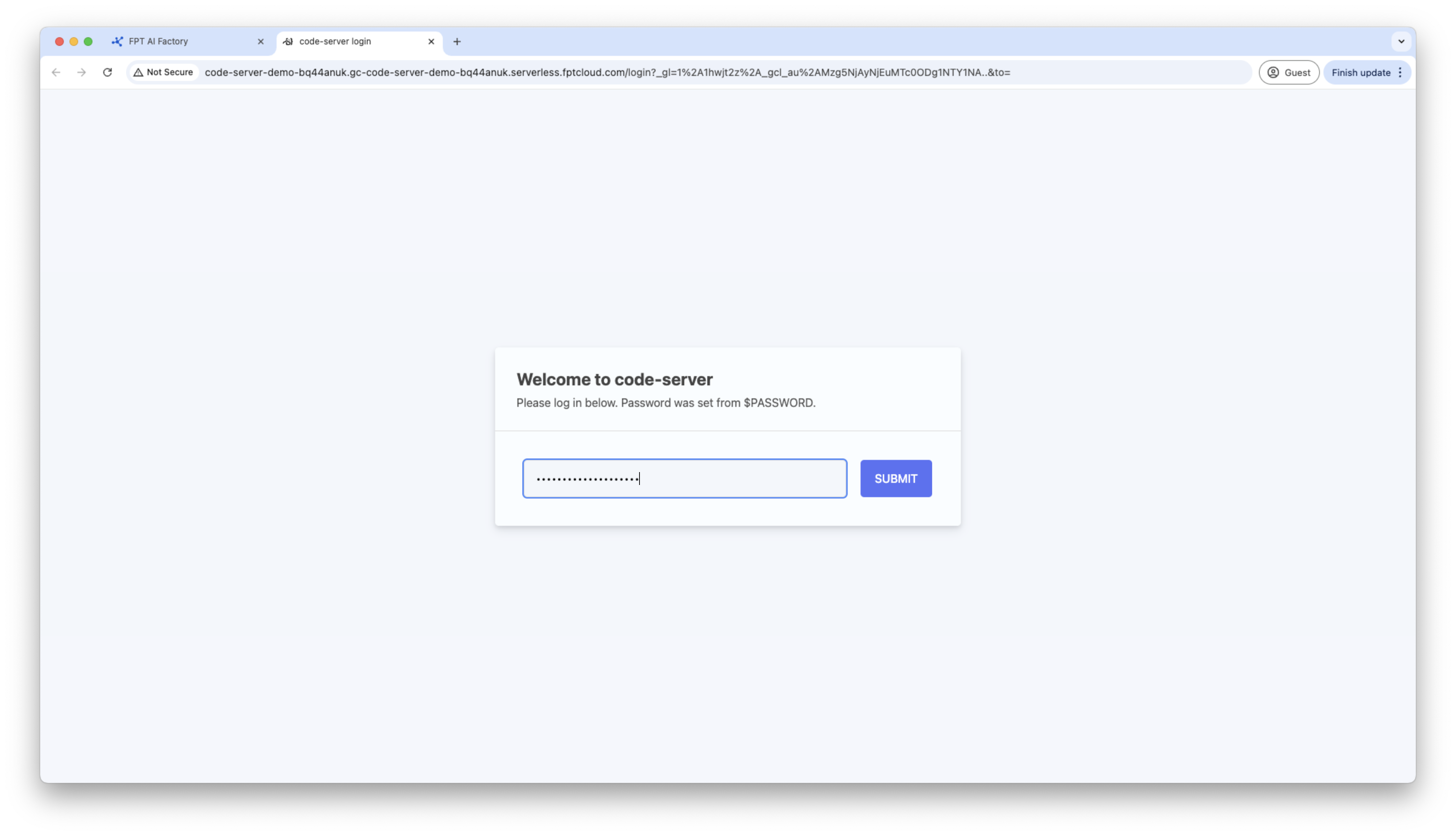
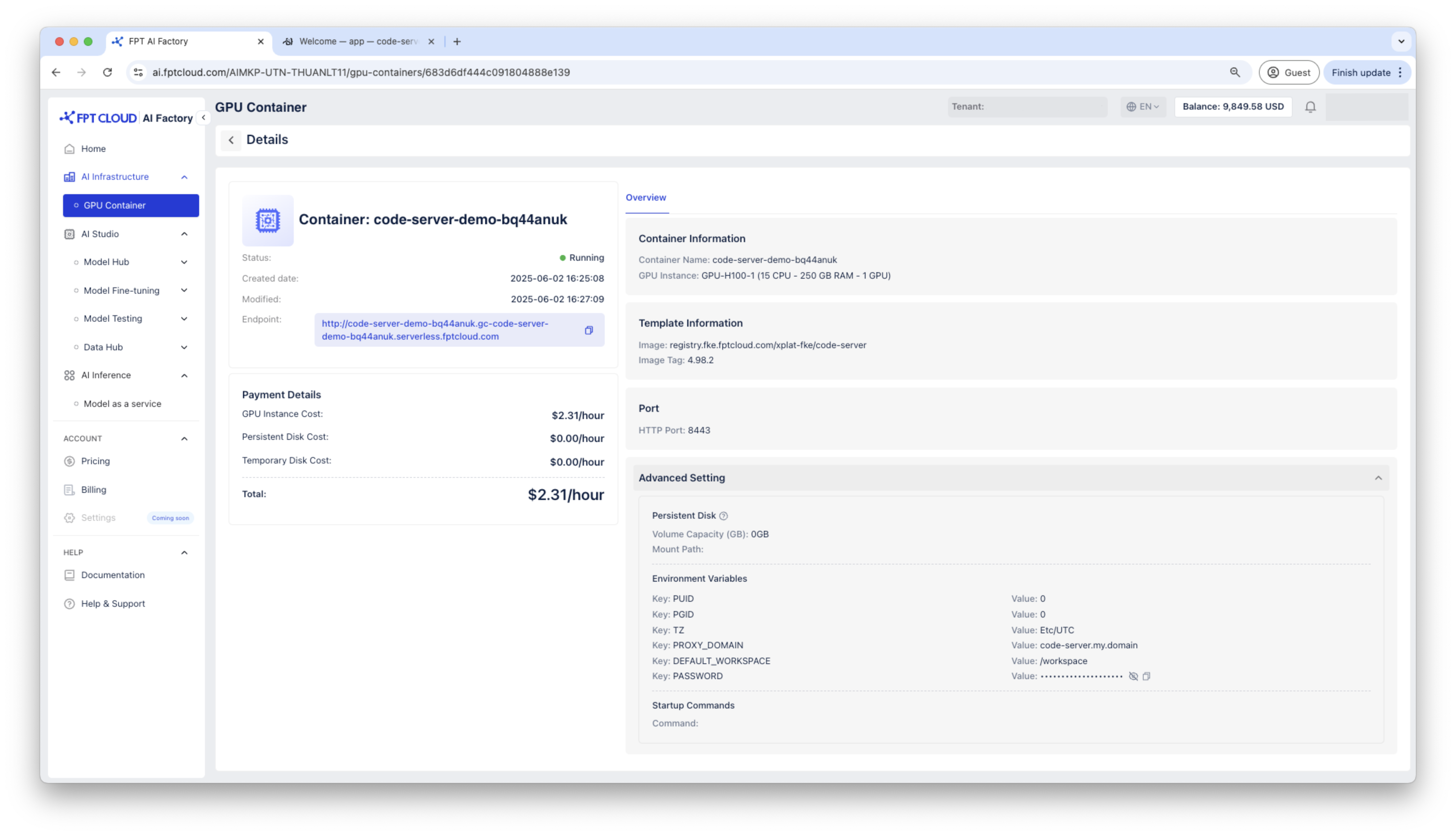 Access to container via HTTP endpoint, the Code Server container will ask for the password, please use the password generated in container details to connect.
Access to container via HTTP endpoint, the Code Server container will ask for the password, please use the password generated in container details to connect.
Step 2: Install python3, pip
Copysudo apt update && sudo apt install -y python3 python3-pip python3-venv git
Step 3: Active virtual environment
Using virtual environment to install required python packages and run training code
Copypython3 -m venv ~/venv
source ~/venv/bin/activate
Step 4: Install required python packages
Copypip install --upgrade pip
pip install scikit-learn scipy
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install datasets evaluate accelerate
Step 5: Clone Hugging Face transformers from Github
Copycd /workspace
git clone https://github.com/huggingface/transformers.git
pip install –e .
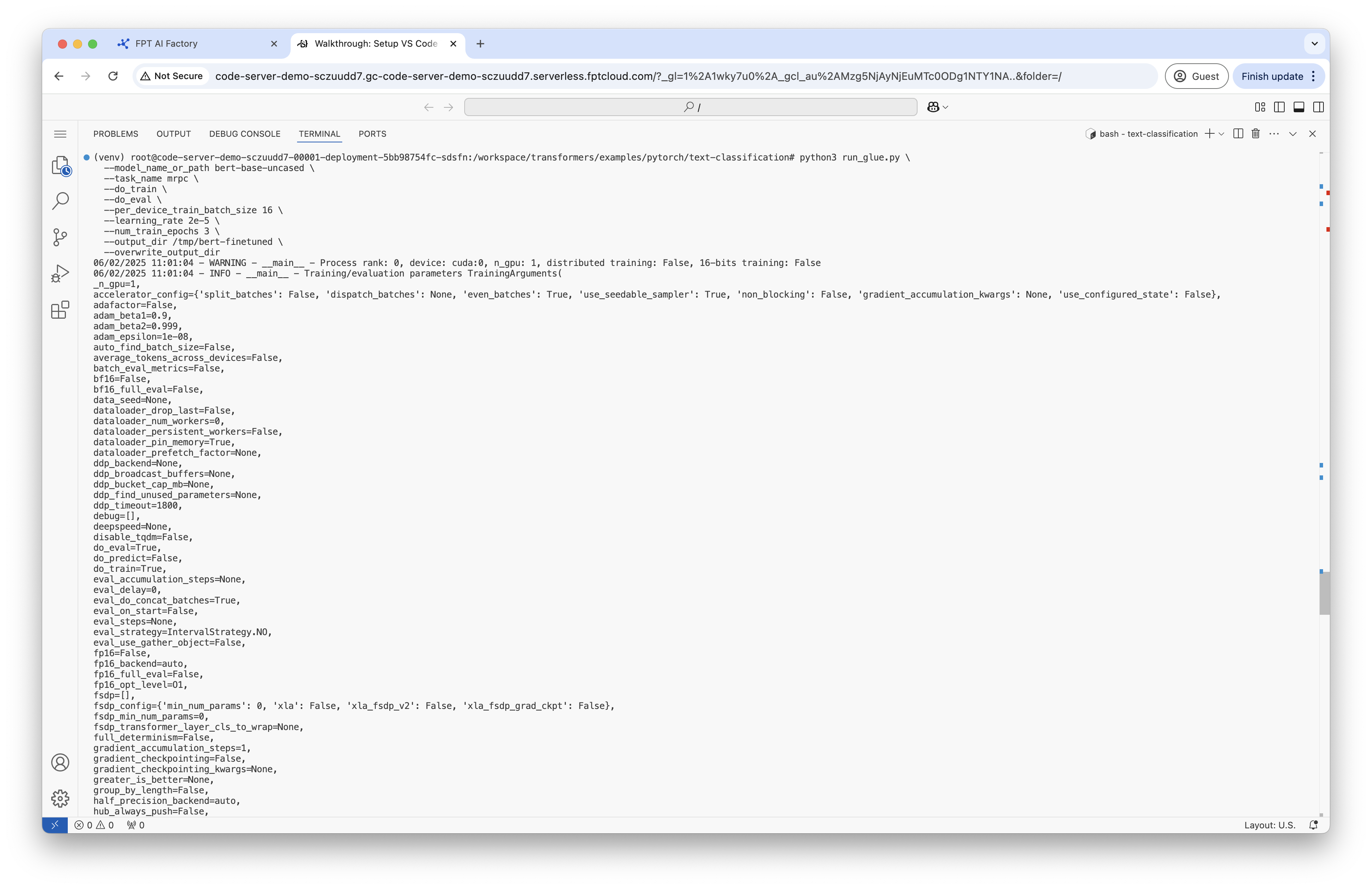
Step 6: Finetune BERT on GLUE MRPC.
Your output will be stored at /tmp/bert-finetuned. In this step, you will fine-tune the pre-trained BERT model on the Microsoft Research Paraphrase Corpus (MRPC) task from the GLUE benchmark. This means the model will learn to classify whether two sentences are paraphrases (have the same meaning) or not.
Copycd /workspace/transformers/examples/pytorch/text-classification
python3 run_glue.py
--model_name_or_path bert-base-uncased
--task_name mrpc
--do_train
--do_eval
--per_device_train_batch_size 16
--learning_rate 2e-5
--num_train_epochs 3
--output_dir /tmp/bert-finetuned
--overwrite_output_dir
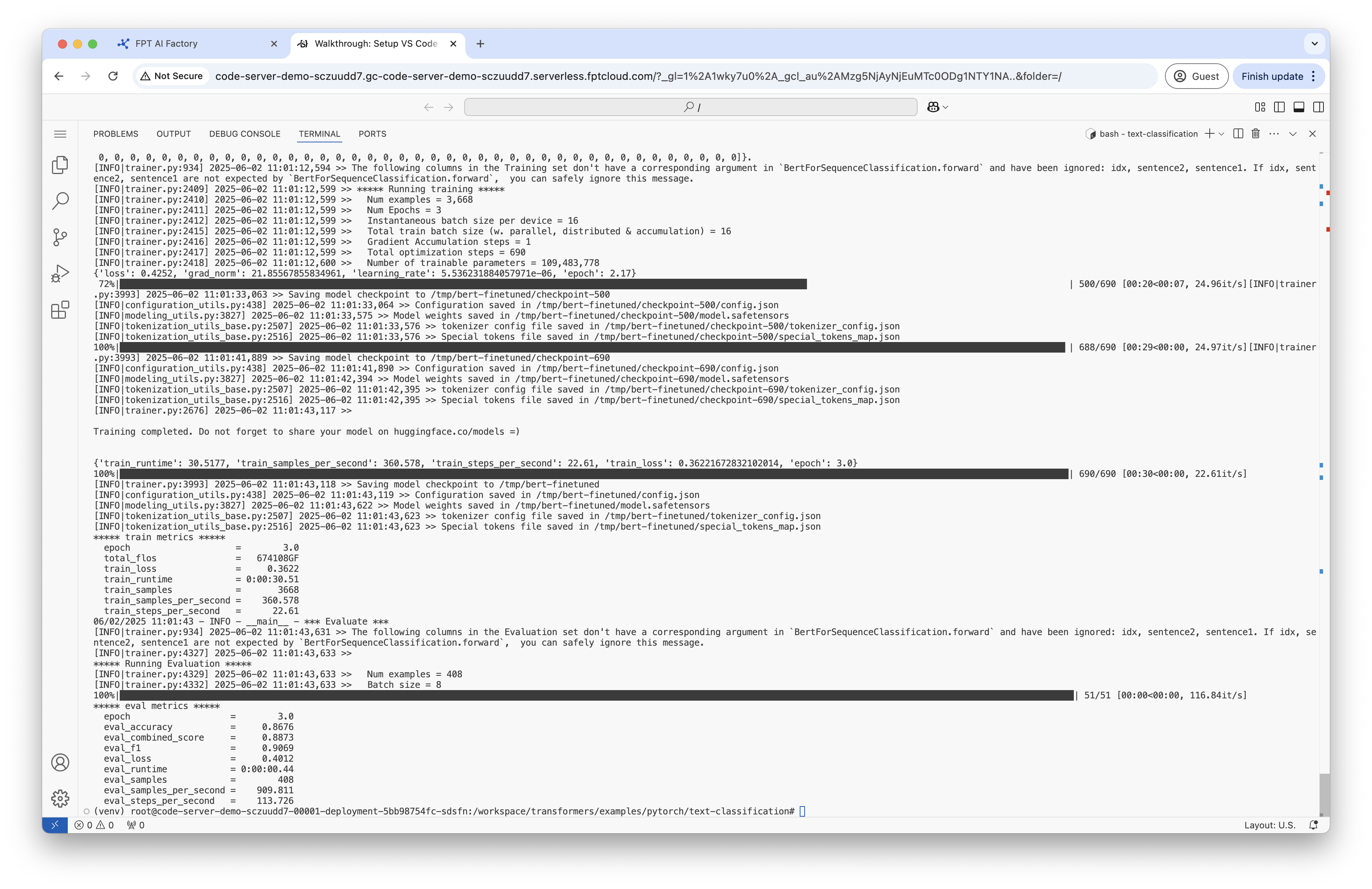
Step 7: Test model
Create a file contains test script called test.py
Copyfrom transformers import BertTokenizer, BertForSequenceClassification
import torch
model_path = "/tmp/bert-finetuned"
model = BertForSequenceClassification.from_pretrained(model_path)
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
sentence1 = "This is a great example!"
sentence2 = "This is a demo for code server GPU Container!"
inputs = tokenizer(sentence1, sentence2, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
predicted_class = torch.argmax(logits, dim=1).item()
label_map = {0: "not paraphrase", 1: "paraphrase"}
print(f"Sentence: {sentence1}")
print(f"Sentence: {sentence2}")
print(f"Predicted Class: {predicted_class} ({label_map[predicted_class]})")
Run file test.py to test the finetuned model
Copypython3 test.py
![]()