MPS GPU共有
MPSはNVIDIA GPUの機能で、複数のコンテナが同一の物理GPUを共有できます。
MPSはGPUリソースの分割においてMIGより優れており、最大48個のコンテナが同時にGPUを使用できます。
MPSはCUDAのNVIDIA Multi-Process Serviceをベースにしており、複数のCUDAアプリケーションが1つのGPU上で同時に実行できます。
MPSを使用すると、ユーザーはGPUのレプリカ数を事前に定義できます。この値は、1つのGPUにアクセスして使用できるコンテナの最大数を示します。
さらに、コンテナ内に以下の環境変数を設定することで、各コンテナのGPUリソースを制限できます:
CUDA_MPS_ACTIVE_THREAD_PERCENTAGECUDA_MPS_PINNED_DEVICE_MEM_LIMIT
MPSの動作についての詳細は、https://docs.nvidia.com/deploy/mps/ をご覧ください。
FPTCloud K8s GPUサービスでのMPS設定
以下のイラストに示すように、worker group初期化時にGPU worker groupにMPSを使用するよう設定できます:
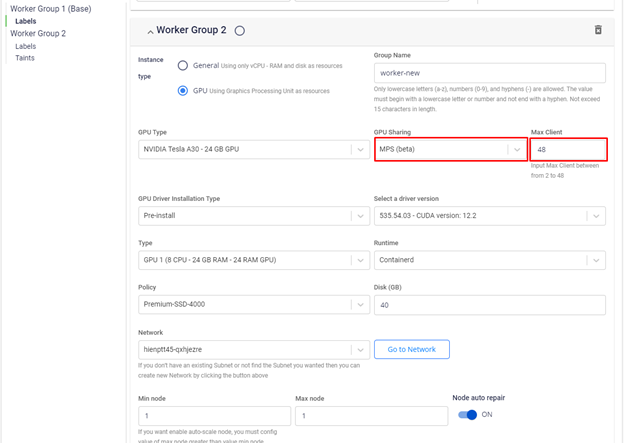
この設定により、GPUは48つの部分に「分割」され、各部分は元の物理GPUの演算能力とメモリの1/48を持ちます。
MPSの確認
以下のコマンドでGPUノードのMPS設定を確認できます:
kubectl describe nodes $NODE_NAME
出力:
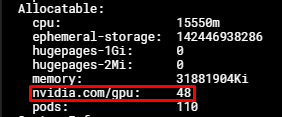
この時点で、ポッドに最大48の nvidia.com/gpu リソースを要求できます。各 nvidia.com/gpu リソースは元の物理GPUの演算能力とメモリの1/48に相当します。
ノードが2つのGPUを使用している場合、96の nvidia.com/gpu リソースが表示されます。
重要な注意事項
- コンテナが要求する
nvidia.com/gpuリソースは1でなければなりません。 - 最大クライアント数は48、最小は2です。物理GPUリソースはすべてのmax clientに均等に分割されます。
- コンテナはMPS共有モードでエラーが発生しないよう、単一のプロセスを実行します。
- ワークロードデプロイメントマニフェストに
hostIPC: trueフィールドが必要です。 - MPSにはエラー封じ込めとワークロード分離に関する制限があります。使用前に必ず確認・検討してください。