MPS GPU sharing
MPS is an NVIDIA GPU feature that allows multiple containers to share the same physical GPU.
MPS has advantages over MIG in terms of GPU resource partitioning — up to 48 containers can use the GPU simultaneously.
MPS is based on NVIDIA's Multi-Process Service for CUDA, which allows multiple CUDA applications to run concurrently on a single GPU.
With MPS, users can pre-define the number of replicas for a GPU. This value tells us the maximum number of containers that can access and use a GPU.
In addition, you can limit GPU resources for each container by setting the following environment variables in the container:
CUDA_MPS_ACTIVE_THREAD_PERCENTAGECUDA_MPS_PINNED_DEVICE_MEM_LIMIT
To learn more about how MPS works, visit: https://docs.nvidia.com/deploy/mps/
Configuring MPS on FPTCloud K8s GPU service
You can configure a GPU worker group to use MPS during worker group initialization as shown in the following illustration:
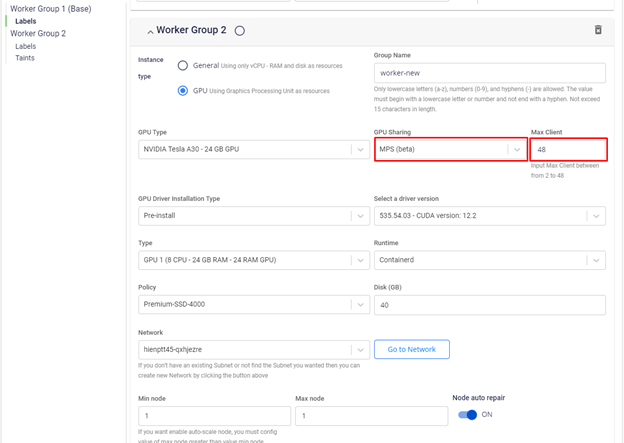
With this configuration, the GPU is "divided" into 48 parts, each with 1/48 of the compute capability and memory of the original physical GPU.
Verify MPS
You can check the MPS configuration on your GPU node with:
kubectl describe nodes $NODE_NAME
Output:
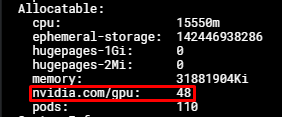
At this point, you can request up to 48 nvidia.com/gpu resources for your pods. Each nvidia.com/gpu resource corresponds to 1/48 of the compute capability and memory of the original physical GPU.
If your node uses 2 GPUs, 96 nvidia.com/gpu resources will be shown.
Important notes
- The
nvidia.com/gpuresource a container requests must equal 1. - The maximum number of clients is 48, the minimum is 2. Physical GPU resources are divided equally among all max clients.
- A container runs a single process to ensure MPS sharing mode does not encounter errors.
- The
hostIPC: truefield is required in the workload deployment manifest. - MPS has limitations regarding error containment and workload isolation. Please review and consider these before use.