FPT CloudでのSLURM
FPT Managed GPU Cluster はオープンソースのK8sプラットフォームをベースに構築され、コンテナアプリケーションのデプロイ、スケーリング、管理を自動化します。FPT Managed GPU ClusterはContainer Orchestration、Storage、Networking、Security、PaaSコンポーネントを統合し、クラウド上でアプリケーションを開発・デプロイするための最適な環境をお客様に提供します。
FPT Managed GPU Cluster はFKEが提供するManaged GPU Clusterサービスモデルです。Managed GPU Clusterでは、FPT Cloudがすべてのコントロールプレーンコンポーネントを管理し、ユーザーはWorker Nodeのデプロイと管理を担当します。Managed GPU Clusterにより、ユーザーはK8sクラスターの管理にリソースを費やすことなく、アプリケーションのデプロイに集中できます。
FPT Managed GPU Cluster はオープンソースのKubernetesプラットフォームをベースとしたサービスモデルで、コンテナ化されたアプリケーションのデプロイ、スケーリング、管理を自動化します。Container Orchestration、Storage、Networking、Security、PaaSコンポーネントの統合に加え、GPUリソースも提供して複雑な演算処理をサポートします。
Managed GPU Clusterを使用する前に確認すべき事項:
· Managed GPU Clusterの設置場所: 地理的なリージョンは、使用中のサーバーへのアクセス速度に影響する場合があります。速度を最適化するために、トラフィックの発生源に最も近いリージョンを選択してください。
· 必要なノード数と各ノードの構成: すべてのFPT CloudアカウントにはRAM、CPU、Storage、IPなどのリソースに対して一定のクォータが割り当てられています。そのため、必要なリソース量と最大限度を事前に確認し、FPT Cloudが最適なサポートを提供できるようにしてください。
1. SLURMとKubernetes上のSLURMの紹介
1.1 SLURMの紹介
SLURMはクラスターのリソース管理とジョブスケジューリングに使用される強力なオープンソースプラットフォームです。スーパーコンピューターや大規模計算クラスターのパフォーマンスと効率を最適化するために設計されています。主要コンポーネントが連携して高いシステムパフォーマンスと柔軟性を確保します。以下の図はSLURMの動作方法を示しています。
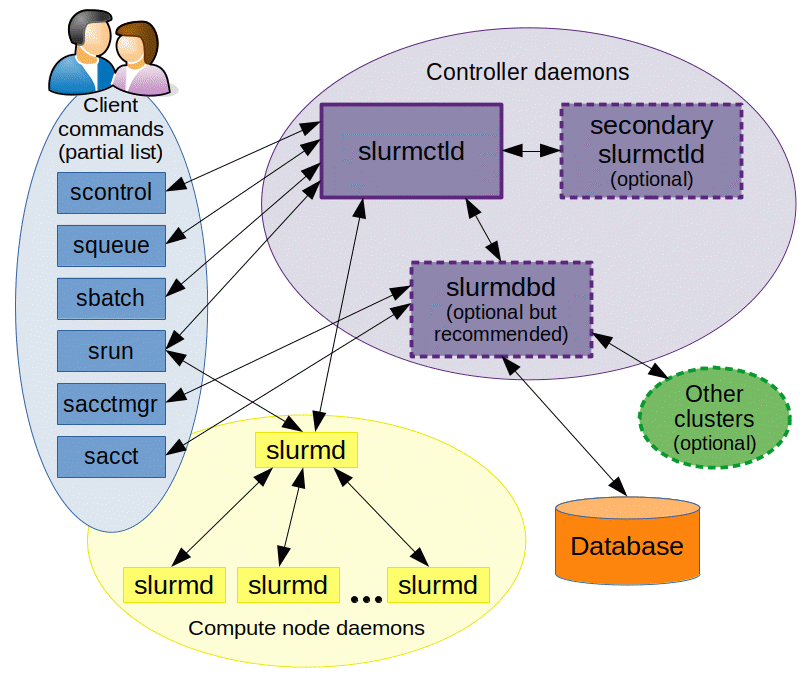
slurmctld: SLURMの制御デーモン。SLURMの「頭脳」とみなされ、システムリソースの監視、ジョブのスケジューリング、クラスター状態の管理を行います。高可用性のために、プライマリslurmctldが障害を起こした場合のサービス中断を防ぐセカンダリslurmctldを設定できます。
slurmd: SLURMノードデーモン。slurmdは各計算ノードにデプロイされます。slurmctldからコマンドを受け取り、ジョブの起動・実行、ジョブステータスの報告、新しいジョブコマンドの準備など、ジョブを管理します。
slurmdbd: SLURMデータベースデーモン。slurmdbdはオプションですが、大規模クラスターの長期管理と監査にとって重要なコンポーネントです。ジョブ履歴と会計情報を保存する集中データベースを維持し、複数のSLURM管理クラスターからデータを集約できます。
SlurmCLI: ジョブ管理とシステム監視のための以下のコマンドを提供します:
scontrol: クラスターの管理とクラスター設定の制御。squeue: キュー内のジョブステータスの照会。srun: ジョブの送信と管理。sbatch: バッチジョブの送信とスケジュールされたリソース管理。sinfo: ノードの可用性を含むクラスター全体のステータス照会。
1.2 なぜSLURM on K8sなのか?
SLURMとKubernetesはどちらも、分散モデル学習や高性能計算(HPC)全般のワークロード管理システムとして機能します。
それぞれに長所と短所があります。SLURMは高度なスケジューリング、効率性、細かなハードウェア制御、会計機能を提供しますが、汎用性に欠けます。一方、Kubernetesは学習以外の多くの目的(推論など)に使用でき、優れた自動スケーリングと自己修復機能を提供します。
残念ながら、現在は両方のソリューションのメリットを組み合わせる方法がありません。また、多くの大手テクノロジー企業がKubernetesをデフォルトのインフラ層として使用しており、専用のモデル学習システムをサポートしていないため、一部のMLエンジニアには選択肢がありません。
SLURM on K8sを使用することで、Kubernetesの自動スケーリングと自己修復機能をSLURMで再利用しながら、システムとの既存の慣れ親しんだインタラクション方法を維持しつつ、独自の機能を実装できます。
1.3 FPT Cloud Managed GPU/K8s ClusterでのSLURMの紹介
SLURM OperatorはSlurmClusterカスタムリソース(CR)を使用して、SLURMクラスターの管理に必要な設定ファイルを定義し、コントロールプレーン管理に関連する問題を解決します。これにより、SLURMが管理するクラスターのデプロイとメンテナンスが簡素化されます。以下の図はFPTCloud Managed GPU/K8s Cluster上のSLURMのアーキテクチャを示しています。クラスター管理者はSlurmClusterを通じてSLURMクラスターをデプロイ・管理できます。SLURM OperatorはSlurmCluster定義に基づいてクラスター内にSLURMコントロールコンポーネントを作成します。SLURM設定ファイルは共有ボリュームまたはConfigMapを通じてコントロールコンポーネントにマウントできます。
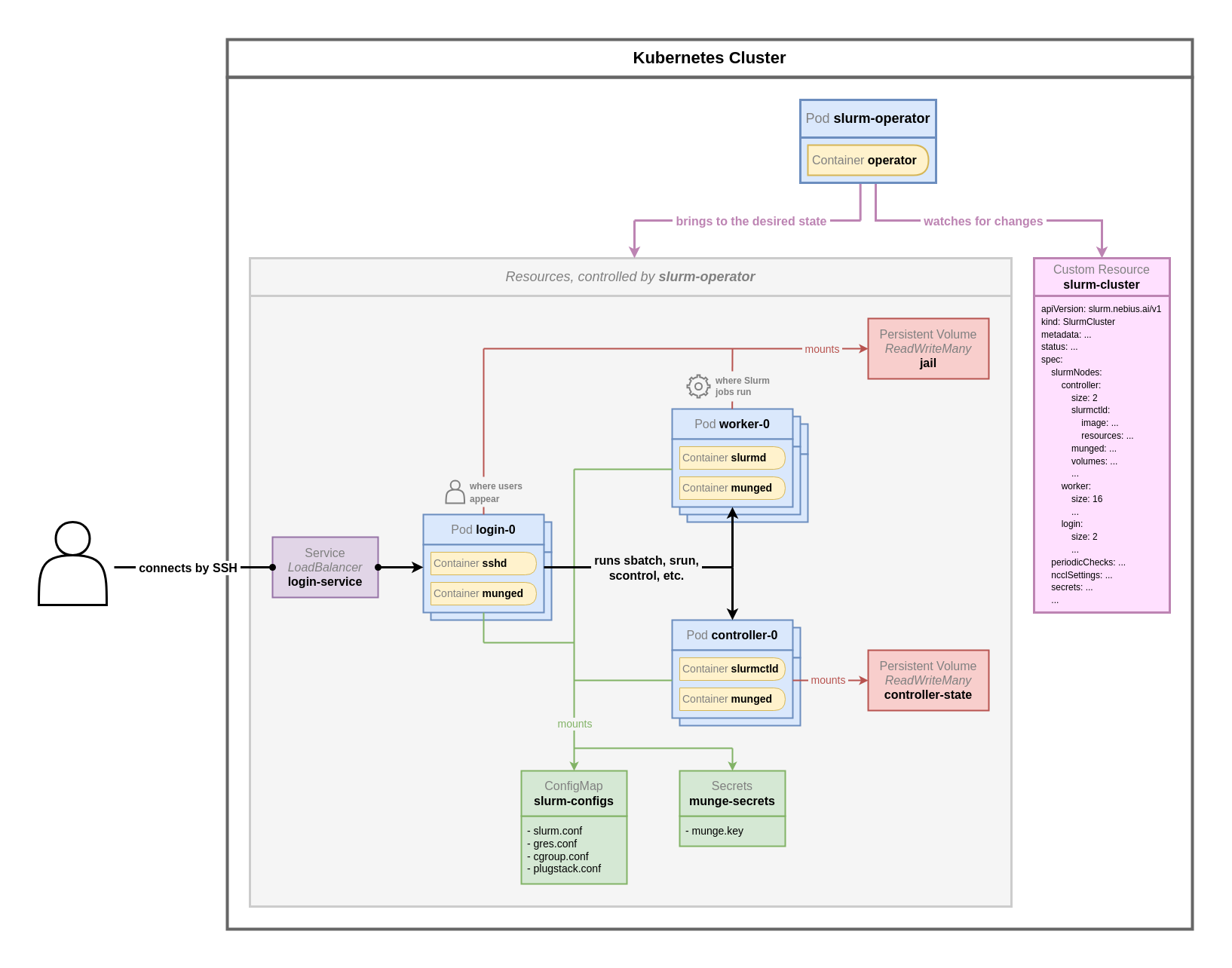
SLURM on K8sデプロイメントモデルでは、ログインノード、ワーカーノードなどのSLURMクラスターコンポーネントがK8s上のPodとして表現されます。このモデルでは、shared-rootボリュームの概念が実装されています:OSのファイルシステムに相当する共有ファイルシステムがデプロイされます。ワーカーノードに送られたすべてのジョブはこの共有ルートボリューム環境で実行されます。これにより、すべてのワーカーノードが常に同じ設定、パッケージ、状態を持つことが手動管理なしに保証されます。つまり、1つのノードにパッケージをインストールすると、そのパッケージは自動的に他のすべてのノードに表示されます。
SlurmClusterカスタムリソースで希望するSLURMクラスターを定義するだけで、SLURM OperatorがSlurmCluster CRで定義した状態に従ってSLURMクラスターのデプロイと管理を行います。
2. インストールガイド
2.1 K8s上にSLURMクラスターをデプロイする
前提条件:
- ダイナミックボリュームプロビジョニングが有効で、十分なストレージクォータが残っているK8sクラスター。
- ReadWriteManyボリュームをプロビジョニングできるStorageClassが少なくとも1つあること。
手順1: GPU softwareインストールセクションでSLURM Operator、GPU Operator、Network Operatorをインストールし、すべてがready状態になるまで待ちます。
手順2: K8sクラスターで、共有ルートスペースとコントローラーノードデータを保持するPersistent Volumeを事前に作成します。
SLURM on K8sデプロイメントモデルのボリュームに注意してください:
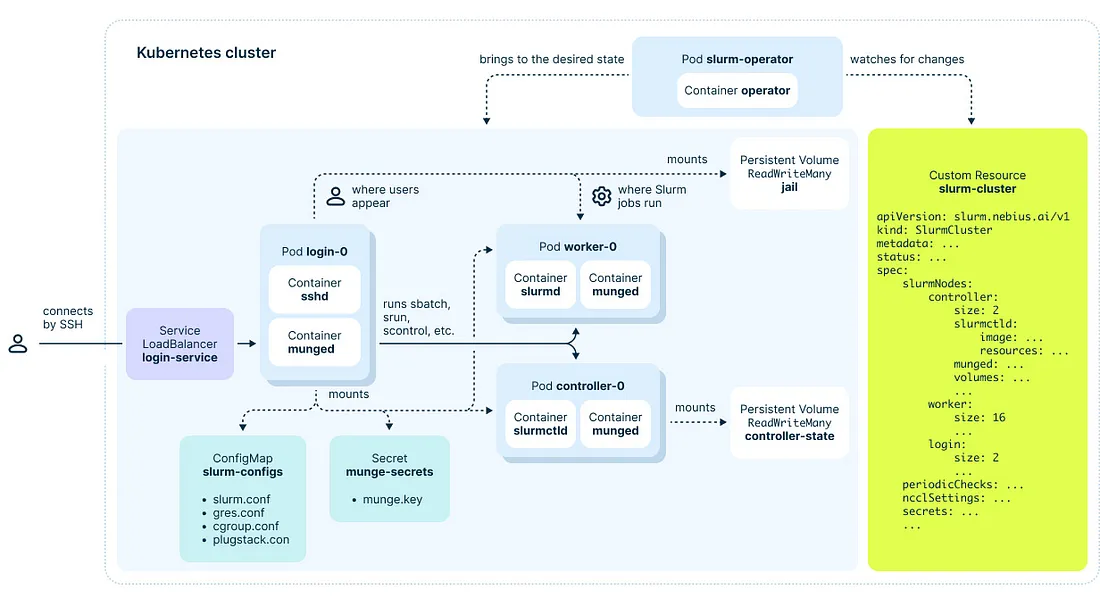
各ボリューム:
· jail-pvc: ワーカーノードとログインノードにマウントされ、共有サンドボックスとして機能します。ジョブが実行されユーザーが操作する環境です。このボリュームはOSファイルシステムを保持するために少なくとも40Gi必要です。
· controller-spool-pvc: クラスター設定情報を保存し、コントローラーノードに配置されます。
jail-pvc.yaml:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: jail-pvc
namespace: fpt-hpc
spec:
storageClassName: default
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100Gi
controller-spool-pvc.yaml(slurm operatorバージョン >= 2.0.0では不要):
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: controller-spool-pvc
namespace: fpt-hpc
spec:
storageClassName: default
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
注意:
- これらのボリュームはどちらも必須で、ReadWriteManyメカニズムを提供する必要があります。PVC名は上記のとおり変更しないでください。
- 便宜のため、FPTcloud managed K8sのダイナミックボリュームプロビジョニングメカニズムを使用しています。
- 本番環境では、SLURMクラスターの移行とメンテナンスを容易にするために、ファイルサーバーの静的パーティションからルートボリュームをマウントすることをお勧めします。
手順3: SLURM cluster CR Helmチャートをダウンロードして希望の設定を定義します。
helm repo add xplat-fke https://registry.fke.fptcloud.com/chartrepo/xplat-fke
helm repo update
helm repo list
helm search repo slurm
helm pull xplat-fke/helm-slurm-cluster --version 1.14.10 --untar=true
注意:slurm-clusterのバージョンをSLURM Operatorのバージョンに合わせてください。
SLURMクラスターのパラメーターについて詳しく知るには、セクション3:SLURMクラスターカスタムリソースのパラメーター説明をお読みください。
cd helm-slurm-cluster/
vi values.yaml
ダウンロードしたフォルダーのvalues.yamlファイルで、以下の重要なフィールドを更新します:
| フィールド名 | 説明 |
|---|---|
| slurmNodes.worker.size | ワーカーノード数 |
| slurmNodes.worker.size.spool.volumeClaimTemplateSpec.storageClassName | ワーカーノード状態保存用PVのStorageClass |
| slurmNode.login.sshRootPublicKeys | SLURMクラスター内のrootユーザーの公開鍵リスト |
| SlurmNode.accounting.mariadbOperator.storage.volumeClaimTemplate.storageClassName | slurmdbd nodeのデータ保存用PVのStorageClass |
希望どおりにクラスターを設定したら、以下のコマンドを実行します:
helm install fpt-hpc ./ -n fpt-hpc
手順4: すべてのSLURMポッドがRunning状態になるまで待ちます。K8s上のSLURMクラスターの初回インストールには約20分かかり、フェーズ1(セットアップジョブの実行)とフェーズ2(SLURMコンポーネントポッドのインストール)の2フェーズがあります。
すべてのコンポーネントがready状態になったら、ログインノードのパブリックIPを確認します:
kubectl get svc -n fpt-hpc | grep login
SLURMクラスターのheadノードにSSHします:
ssh root@IP_login_svc
nodeshellを使用する場合:
chroot /mnt/jail
sudo -i
確認テストを実行します:
srun --nodes=2 --gres=gpu:1 nvidia-smi -L
salloc --nodes=1 --ntasks=1 --mem=4G --time=00:20:00 --gres=gpu:1
2.2 SLURMクラスターでサンプルジョブを実行する
SLURMクラスターへのログインが成功したら、minGPTモデルのトレーニングでクラスターの動作をテストします:
手順1: pytorch/examplesリポジトリをクローンします。
mkdir /shared
cd /shared
git clone https://github.com/pytorch/examples
手順2: minGPT-ddpフォルダーに移動し、必要なパッケージをインストールします。
cd examples/distributed/minGPT-ddp
pip3 install -r requirements.txt
pip3 install numpy
shared rootメカニズムのおかげで、コマンドを一度実行するだけで、パッケージは他のすべてのワーカーノードに自動的に同期されます。
注意:本番環境では、グローバル環境に直接パッケージをインストールする代わりに、condaエビロンメントまたはコンテナを使用してトレーニング環境を作成することをお勧めします。
手順3: SLURMスクリプトファイルを編集します。
vi mingpt/slurm/sbatch_run.sbatch
注意:sbatch_run.shファイル内のmain.pyへのパスを、mingptフォルダー内の実際のmain.pyのパスに更新してください。
手順4: サンプルSLURMジョブを実行します。
sbatch mingpt/slurm/sbatch_run.sh
手順5: 結果を確認します。
squeue
scontrol show job job_id
cat log.out
3. SLURMクラスターのカスタムリソースパラメーター説明
セクション2では最も重要なパラメーターを説明しました。このセクションでは、SLURMクラスターに定義されたすべての属性についてさらに詳しく説明します。ダウンロードしたSLURMクラスターカスタムリソースのvalues.yamlファイルのコメントも参照してください。
| 属性 | サンプル値 | 説明 |
|---|---|---|
| clusterName | "fpt-hpc" | クラスター名(変更しないこと)。 |
| k8sNodeFilters | N/A | K8sクラスターをGPUノード(SLURMワーカーのデプロイ用)と非GPUノードの2つのリストに分けます。GPUノードのみのクラスターの場合、両リストは同じにできます。 |
| volumeSources | values.yamlを参照 | SLURMコンポーネント(ワーカー、ログイン、コントローラーノードなど)を表すコンテナが使用するPVCを定義します。 |
| periodicChecks | N/A | 各ノードの健全性を確認する定期ジョブ。GPUノードに問題がある場合、そのノードをdrainします。 |
| slurmNodes | N/A | SLURMクラスター内のコンポーネントノード(ログイン、ワーカーなど)の数と設定を定義します。 |
| slurmNodes.accounting | enabled: true, mariadbOperator: ... | 会計ノードを設定します。MariaDB Operatorを使用してデータベースを作成します。外部データベースも使用できます(values.yamlを参照)。 |
| slurmNodes.controller | size: 1, k8sNodeFilterName: "no-gpu", ... | コントローラーノードの設定:spoolとjailボリュームがマウントされた1つのコントローラーノード。 |
| slurmNodes.worker | size: 8, k8sNodeFilterName: "gpu", gpu: 8, ... | ワーカーノードの設定:8つのワーカーノード、各ノードに8つのGPU、jailボリューム(共有ルートスペース)がマウントされています。 |
| slurmNodes.login | size: 2, sshd port: 22, sshRootPublicKeys: [...] | ログインノードの設定:LoadBalancerサービスを通じてsshdを公開する2つのログインノード、rootユーザー用公開鍵の使用、コントローラーおよびワーカーノードと同様のボリューム。 |
| slurmNodes.exporter | enabled: true, size: 1, ... | モニタリング用のnode exporterをインストールします。 |
4. よくあるユースケース
4.1 ユーザーの追加/ログイン管理
ユーザーの追加
rootのSSHキーを追加するには、SLURMクラスターCRを編集します:
kubectl edit SlurmCluster fpt-hpc -n fpt-hpc
ログインノード設定セクションで sshRootPublicKeys に移動し、希望する公開鍵を追加します。
通常ユーザーを追加するには、Linuxホストへのユーザー追加と同様の手順を実行します:
sudo adduser user_name
ログインの変更
デフォルトでは、ログインノードはパブリックLoad Balancerを通じて公開されていますが、これは一部の要件に適していない場合があります。LBタイプをプライベートに変更したり、ポートフォワーディングを使用してSLURMクラスターにアクセスしたり、ポータルとLBノードでカスタマイズしたりできます。
4.2 ワーカーノードのスケールアップ・ダウン
ワーカーノード数やその他のノードタイプの数を変更するには、SLURMクラスターCRを編集します:
kubectl edit SlurmCluster fpt-hpc -n fpt-hpc
ワーカーノード設定に移動し、size を希望のワーカーノード数に変更します。
注意:
- スケールアップ時、新しいノードはSLURMコントローラーノードのワーカーノードリストに自動的に追加され、ジョブを実行できる状態になります。
- スケールダウン時は、SLURMコントローラーでノードを手動で削除する必要があります:
scontrol delete nodeName=node_name_to_delete
- クラスター内のノードリストは常に
worker-[0, (size - 1)]です。
4.3 SLURMクラスターを別のK8sクラスターに移行する
K8sとネットワークファイルストレージの柔軟性により、SLURMクラスターを1つのK8sクラスターから別のクラスターに簡単に移行できます。新しいSLURM K8sクラスターで jail-pvc を再マウント・再作成し、SLURM K8s作成手順を再実行するだけです。
4.4 SLURMクラスターへの外部ボリュームのマウント
SLURMクラスターにボリュームをマウントするには、まずボリュームを作成し、K8sでPVとPVCとしてデプロイします。以下の例ではダイナミックプロビジョニングを使用します(本番環境ではデータ安全のためにスタティックプロビジョニングを推奨)。
手順1: PVCを作成します。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: jail-submount-mlperf-sd-pvc
spec:
storageClassName: default
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100Gi
手順2: SLURMクラスターCRの volumeSource フィールドを編集してこのボリュームを宣言します。
kubectl edit SlurmCluster fpt-hpc -n fpt-hpc
volumeSources:
- name: controller-spool
persistentVolumeClaim:
claimName: "controller-spool-pvc"
readOnly: false
- name: jail
persistentVolumeClaim:
claimName: "jail-pvc"
readOnly: false
- name: mlperf-sd
persistentVolumeClaim:
claimName: "jail-submount-mlperf-sd-pvc"
readOnly: false
手順3: SLURMクラスターのログインノードとワーカーノードにボリュームをマウントします。
ログインノードの場合:
volumes:
jail:
volumeSourceName: "jail"
jailSubMounts:
- name: "mlcommons-sd-bench-data"
mountPath: "/mnt/data-hps"
volumeSourceName: "mlperf-sd"
ワーカーノードの場合:
volumes:
spool:
volumeClaimTemplateSpec:
storageClassName: "xplat-nfs"
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: "120Gi"
jail:
volumeSourceName: "jail"
jailSubMounts:
- name: "mlcommons-sd-bench-data"
mountPath: "/mnt/data-hps"
volumeSourceName: "mlperf-sd"
注意:マウントパスはワーカーノードとログインノードで同じである必要があります。
4.5 Dockerの使用
HPC環境では、ApptainerやEnroot&PyxisなどのコンテナランタイムがDockerよりも優先して使用されます。しかし、これらのランタイムはイメージのビルドやプッシュ、さらにはDockerに慣れたユーザーにとっての実行(DockerはSLURMでは推奨されません)において使いにくい面があります。
これらのユーザーをサポートするため、SLURMクラスターのshared rootボリュームにDockerをインストールしており、クラスター内のすべてのノードがDockerを使用できます。ただし、これはジョブがノードのすべてのリソースを使用することを要求します。Dockerで起動されたジョブはApptainerのようにリソースを制限できないためです。
ユーザーは常に -N と --exclusive を追加してDockerで起動されたジョブにすべてのノードリソースを付与することを推奨します。
4.6 SSHの使用
以前のバージョンのSLURM Operatorでは、ユーザーはkubectlを介してワーカーノードに直接シェルすることでしかワーカーノードにアクセスできませんでした。
バージョン2.0.0から、SLURM Operatorはkubectl shellアクセスの代わりにワーカーノード上のSSHをサポートしています。ワーカーノードのユーザーアカウントはログインノードと同期されています。
ログインノードの場合、デフォルトではロードバランサーのIPにSSHすると、ロードバランサーはSSHセッションをランダムなログインノードにルーティングします。
TmuxなどのSSHツールを使用していて常に特定のノードにSSHしたい場合は、以下のコマンドを使用します:
ssh -J username@public_endpoint username@login-number -i path_to_private_key