FPT Kubernetes EngineのvGPU機能
FPT Managed GPU Cluster はオープンソースのK8sプラットフォームをベースに構築され、コンテナアプリケーションのデプロイ、スケーリング、管理を自動化します。Container Orchestration、Storage、Networking、Security、PaaSコンポーネントを統合し、クラウド上でアプリケーションを開発・デプロイするための最適な環境を提供します。
FPT Managed GPU Cluster は1つのNVIDIA GPU上で複数のコンテナ/プロセスのためにvGPU機能を提供します。この機能を使用することで、GPUの使用コストを最適化できます。
前提条件
- FPT managed GPU clusterを初期化するために、managed GPU clusterサービスをアクティベートし、ストレージ、パブリックIPなどのクォータが十分にあること。
- GPU OperatorがClusterにインストールされていること。
- Worker groupがPre-installed driverを使用しているか、手動でdriverがインストールされていること。
- Worker groupがGPU worker groupタイプであること。
インストールガイド
手順1: GPU softwareインストールセクションでvGPU schedulerをインストールし、ステータスがreadyになるまで待ちます。
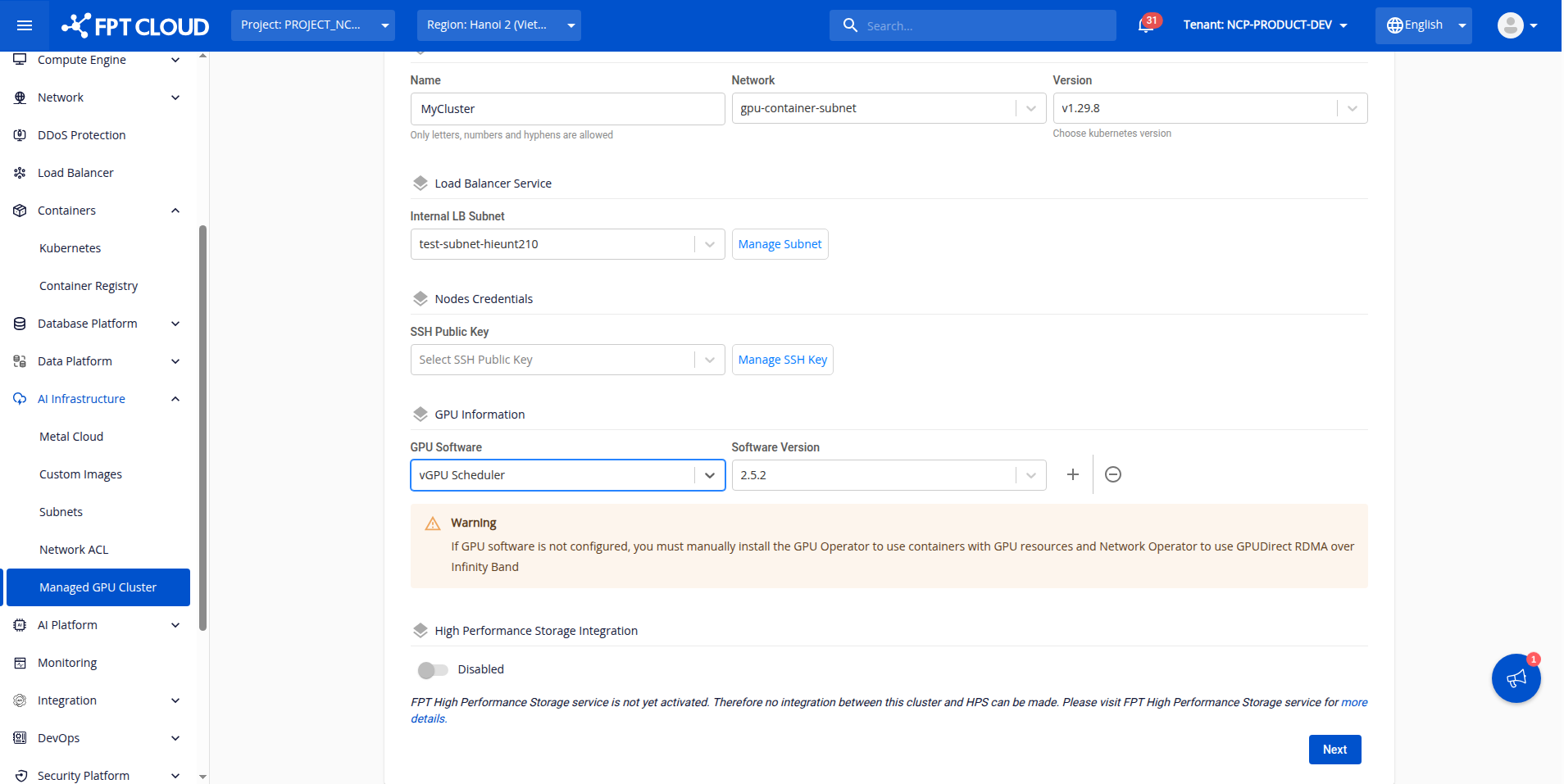
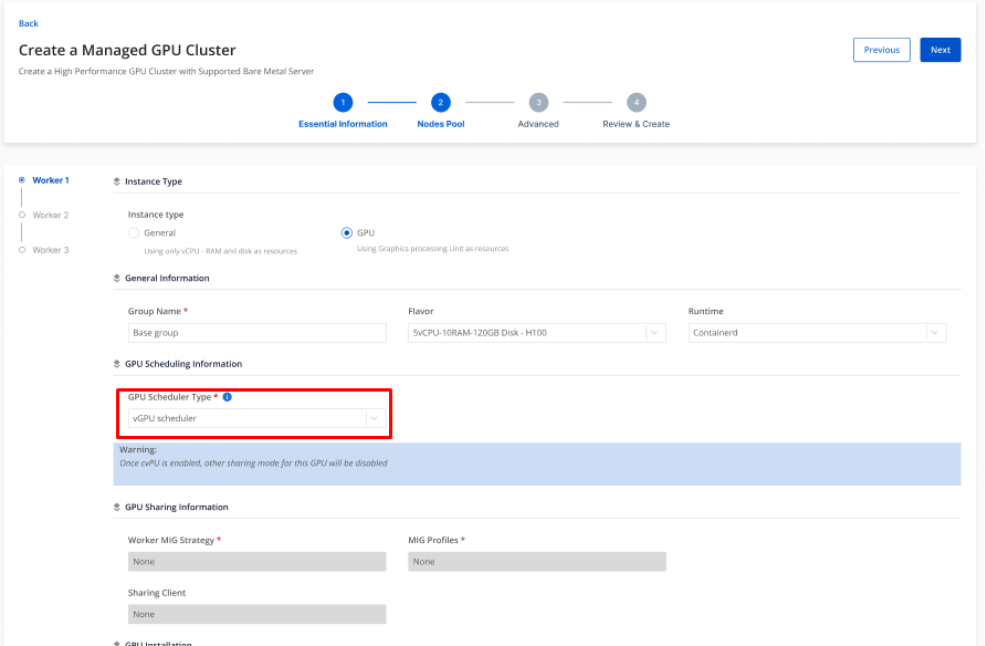
手順2: GPU worker groupタブで、各worker groupにelastic GPU schedulerコンポーネントを有効にするかどうかを選択できます。
注意:
- worker groupにvGPU schedulerを有効にした場合、そのworker group上のMIG、MPS、Time Slicingなどの他のすべての共有モードを無効にする必要があります。
- vGPU schedulerを使用する必要がない場合は、GPU scheduler typeをNoneに設定してください。その場合、通常どおりMIG、MPS、Time SlicingなどのGPU共有ソリューションを使用できます。
- 1つのGPUを共有できるコンテナの最大数は48ですが、全体的なパフォーマンスを確保するために、1つのGPUあたり20以下のvGPUを使用することを推奨します。
手順3: 指定されたノードのvGPU schedulerのステータスを確認します。
vGPU device pluginポッドがready状態であることを確認する
コマンド:
kubectl get pods --all-namespaces --field-selector spec.nodeName=<node_name> -o wide | grep device-plugin
![]()
ノード上のvGPUリソースを確認する:
kubectl describe node <node_name> | grep Allocatable -A9
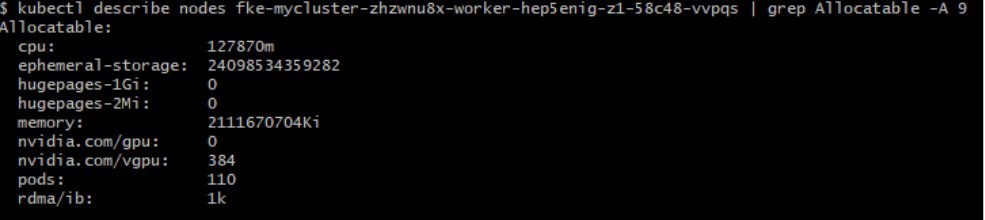
nvidia.com/vgpu リソースが表示され、値が1より大きい場合、ノード上のvGPUは使用可能な状態です。
手順3: vGPUを使用してKubernetes上にサンプルワークロードをデプロイします。
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-gpt2
spec:
replicas: 1
selector:
matchLabels:
app: vllm-gpt2
template:
metadata:
labels:
app: vllm-gpt2
spec:
containers:
- name: vllm
image: vllm/vllm:latest
args:
- --model=gpt2
- --tensor-parallel-size=1
- --port=8000
ports:
- containerPort: 8000
resources:
limits:
nvidia.com/vgpu: 1 # 1 vGPUを要求
nvidia.com/vgpumem: 40000 # コンテナに40000 MiB DRAMを要求
restartPolicy: Always
注意:
nvidia.com/vgpu: 1 は1つの物理GPU上でのvGPU共有を使用することを意味します。nvidia.com/vgpu: 2 を要求する場合、2つの物理GPUが必要です。
結果:
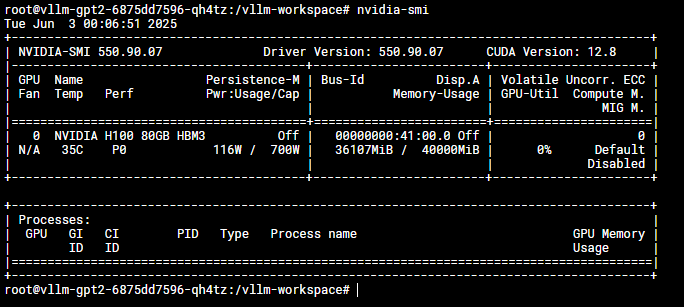
ここでは、VLLMコンテナは最大40000 MiBのGPU DRAMしか使用できません。
vGPU schedulerの機能
FPT Cloud vGPU schedulerは以下の機能を提供します:
1. 柔軟なGPUリソース共有 — 設定可能なパラメーター:
resourceName: "nvidia.com/vgpu"— podが使用するGPUの数(例:2は2つのGPUに対応)resourceMem: "nvidia.com/vgpumem"— podがGPUごとに使用するメモリ(例:3000は3000 MB GPU Memoryに対応)resourceMemPercentage: "nvidia.com/vgpumem-percentage"— vgpumemと同じですが、パーセンテージで表現resourceCores: "nvidia.com/vgpucores"— GPU coreの最大使用量を制限
2. メモリ分離
FPT device pluginでは、コンテナが使用できるリソースの最大量を管理することをサポートしています。コンテナのリソース要求時に nvidia.com/vgpumem フィールドを編集できます。
3. シングルGPU共有とマルチGPU共有
- コンテナのGPUリクエスト(
nvidia.com/vgpu)を変更することで、podが1つまたは2つのGPUを使用できます。 - コンテナが要求する各vGPUのgpumemやgpu coresリソースも変更できます。
注意:
コンテナで nvidia.com/gpu: 2 を設定すると、コンテナは2つの異なる物理GPU上に配置された2つのvGPUを使用することになります(同一物理GPU上の2つのvGPUではありません)。
nvidia.com/vgpumem または nvidia.com/vgpucores を指定しない場合、schedulerはノードの対応するリソースをすべて使用したいと解釈します。
このdevice pluginを有効にした場合、すべてのコンテナがGPUを使用する複数コンテナの単一podは使用しないことを推奨します。
vGPU schedulerとNVIDIA GPU共有ソリューションの比較
| 機能 | FPTCloud vGPU | MPS | Time-slicing | MIG | Nvidia vGPU |
|---|---|---|---|---|---|
| 対象ユースケース | GPUを使用するコンテナ向けの柔軟なGPU共有とスケジューリングポリシー。 | 複数アプリケーションを並列実行し、プロセスが突然停止するリスクと引き換えにパフォーマンスを得る。 | ワークロードをGPUに投入してGPUに残りの処理を任せたいだけの場合の原始的なGPU共有方法。 | QoSと耐障害性を確保したGPU共有。MIGプロファイルの全体的なパフォーマンス低下と柔軟性の低さを受け入れる。 | マルチテナント、複数VMが1つの物理GPUを共有。NVIDIAのライセンスコストを受け入れる。 |
| パーティションタイプ | 論理 | 論理 | 時間的 | 物理的 | 時間的 & 物理的(VM) |
| 最大パーティション数 | 無制限 | 48 | 無制限 | 7 | 変動 |
| SM パフォーマンス分離 | あり(クライアントごとではなく%単位) | あり(クライアントごとではなく%単位) | なし | あり | あり |
| メモリ保護 | あり | あり | なし | あり | あり |
| メモリ帯域幅 | なし | なし | なし | あり | あり |
| エラー分離 | あり | なし | あり | あり | あり |
| 再設定 | プロセス起動時 | プロセス起動時 | タイムスライス期間のみ | アイドル時 | なし |
| テレメトリ | あり | 限定的 | なし | あり(コンテナ内を含む) | あり(ライブマイグレーションを含む) |
| その他注目点 | すべてのGPUをサポート | cudaCapability >= 3.5 | cudaCapability >= 7.0 | cudaCapability >= 8.0(Hopper、Ampere) | ライセンス必要 |