GPU対応Kubernetesクラスターのインストールと初期化
FPT Cloudは以下のGPUカードをサポートしています。
- HanoiおよびSGNリージョン: GPU A30
- Hanoi 2およびJapanリージョン: GPU A30、H100 SXM5、H200 SXM5
必須要件:
- 希望するKubernetesクラスター構成に十分なCPU、GPU、RAM、ストレージ、インスタンスのクォータ。Autoscaleを使用する場合は、GPUクォータが希望する最大ノード数を満たす必要があります(MinノードとMaxノードの設定に注意してください)。
- ネットワークサブネット1つ: KubernetesノードとStaticIPプールが必要です。
クラスター初期化手順
1. GPU A30
ステップ1: FPT Cloudポータル console.fptcloud.com にアクセスし、Kubernetesセクションに移動して「Create a Kubernetes Engine」をクリックします。
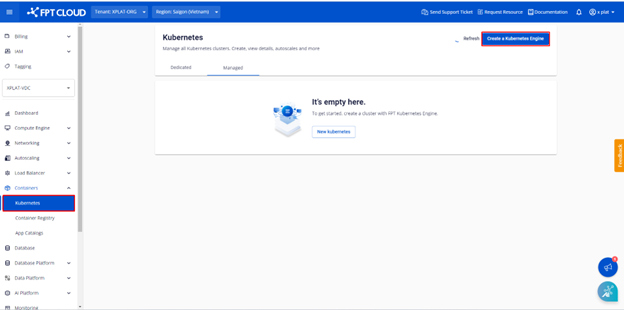
ステップ2: クラスターの基本情報を入力してボタンをクリックします。
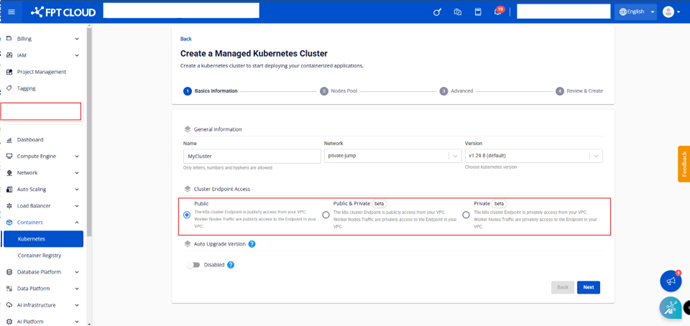
1.1. Basics Information:
-
Name: クラスター名を入力します。
-
Network: KubernetesクラスターのVMをデプロイするために使用するサブネットです。
-
Version: Kubernetesクラスターのバージョンを選択します。
-
Cluster Endpoint Access: Kubernetesクラスターエンドポイントへのアクセス方法を選択します。
- Public: k8sクラスターのAPIサーバーエンドポイントにパブリックインターネットからアクセスできます。ワーカーノードからAPIサーバーへの接続はパブリックネットワーク経由で行われます。
- Public & Private: k8sクラスターのAPIサーバーエンドポイントにパブリックインターネットからアクセスできます。ワーカーノードからAPIサーバーへの接続はプライベートネットワーク経由で行われます。
- Private: k8sクラスターのAPIサーバーエンドポイントはVPC内からのみアクセスできます。ワーカーノードからAPIサーバーへの接続はプライベートネットワーク経由で行われます。
クラスターエンドポイントの選択方法:
- Public: VPC外からKubernetes APIエンドポイントにアクセスする必要がある場合に使用します。
- Public & Private: エンドポイントをパブリックアクセス可能にし、APIサーバーエンドポイントへのアクセスIPをホワイトリストに登録したい場合に使用します。
- Private: VPC内部からのみエンドポイントにアクセスする必要がある場合に使用します。
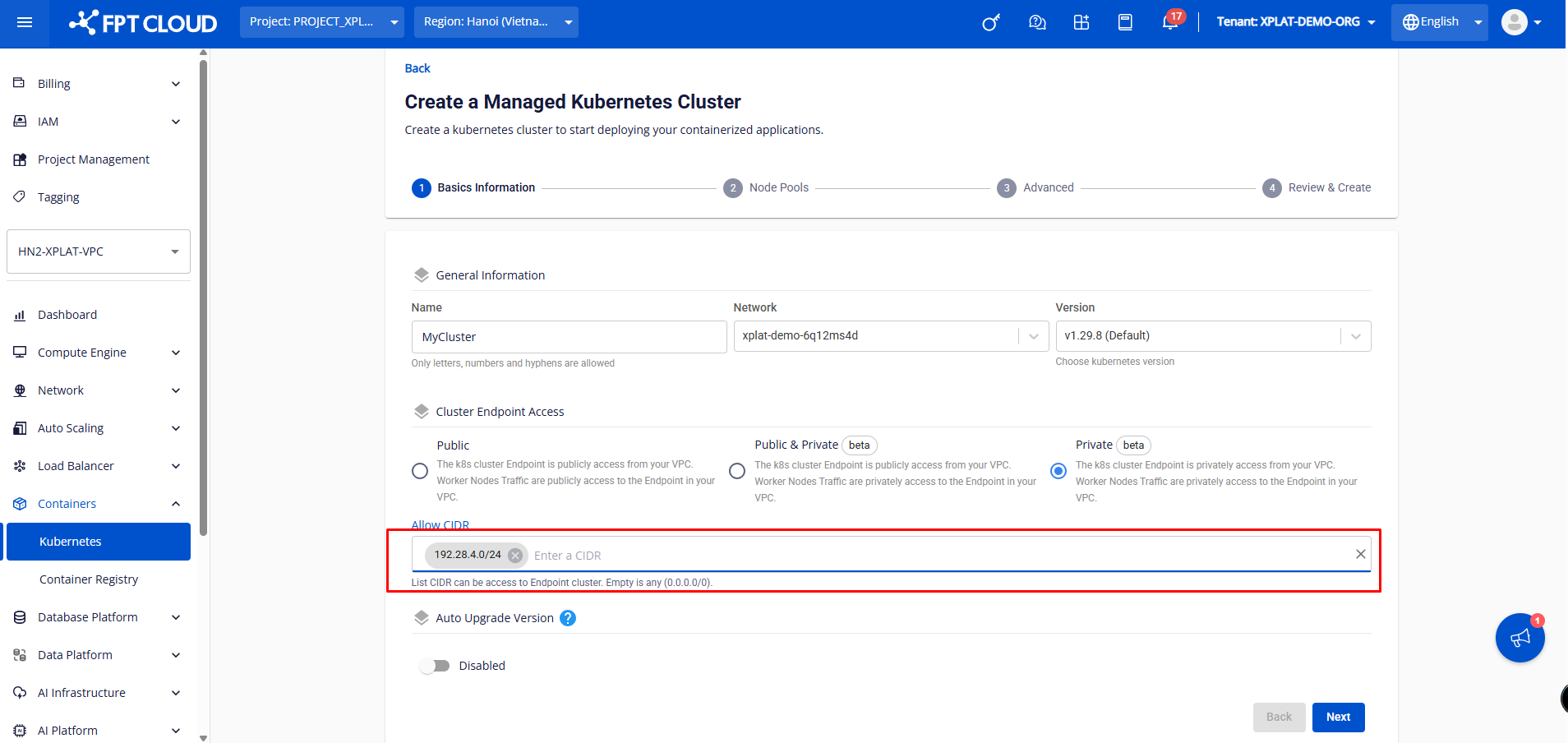
- セキュリティ要件とネットワークアーキテクチャに合ったCluster Endpoint Accessモードを選択してください。
- Public & PrivateまたはPrivateを選択すると、KubernetesクラスターエンドポイントへのアクセスをIPアドレス範囲で制限できる「Allow CIDR」フィールドが表示されます。
Allow CIDRについて:
- CIDR(Classless Inter-Domain Routing)は、Kubernetes APIエンドポイントへのアクセスを許可するIPアドレス範囲を指定するフォーマットです。
- 空白のままにすると、デフォルトは
0.0.0.0/0となり、すべてのIPアドレスからアクセスできます。 - 特定の値(例:
192.168.1.0/24)を入力すると、192.168.1.0〜192.168.1.255の範囲のIPのみがアクセスできます。
高セキュリティが必要な場合は、0.0.0.0/0 ではなく内部IPアドレス範囲に制限してください。
ステップ3: Kubernetesクラスターの設定を入力します。通常のKubernetes設定に加えて、Worker GroupでGPUオプションを設定する必要があります。
- インスタンスタイプ: GPU を選択
- GPUタイプ: Nvidia Tesla A30 を選択
- GPU共有設定を選択
- GPUタイプ設定(CPU / RAM / GPU RAM)を選択
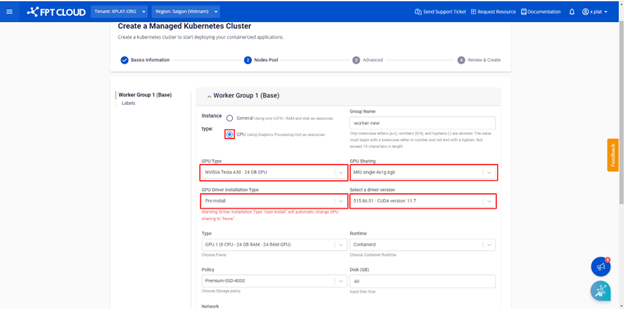
- 「GPU Driver Installation Type」には Pre-install と User-install の2つのオプションがあります。
- ドライバーとは、OSがハードウェア(ここではワーカーのOS(Windows、Ubuntuなど)とGPU)と通信するためのプログラムです。ドライバーがなければOSはGPUを使用できません。
- Pre-install を選択すると、NVIDIAのGPUドライバーがクラスターに自動的に追加されます。
- User-install を選択すると、適切なドライバーバージョンを選択してGPUドライバーを手動でインストールできます。
ステップ4: Createをクリックして初期化情報を確認します。
ステップ5: Kubernetesクラスターの初期化状態を監視します。ステータスがSucceeded(Running)になったら、アプリケーションをデプロイできます。
2. GPU H100 SXM5
ステップ1: FPTポータルメニューで Containers > Kubernetes > Create a Kubernetes Engine を選択します。
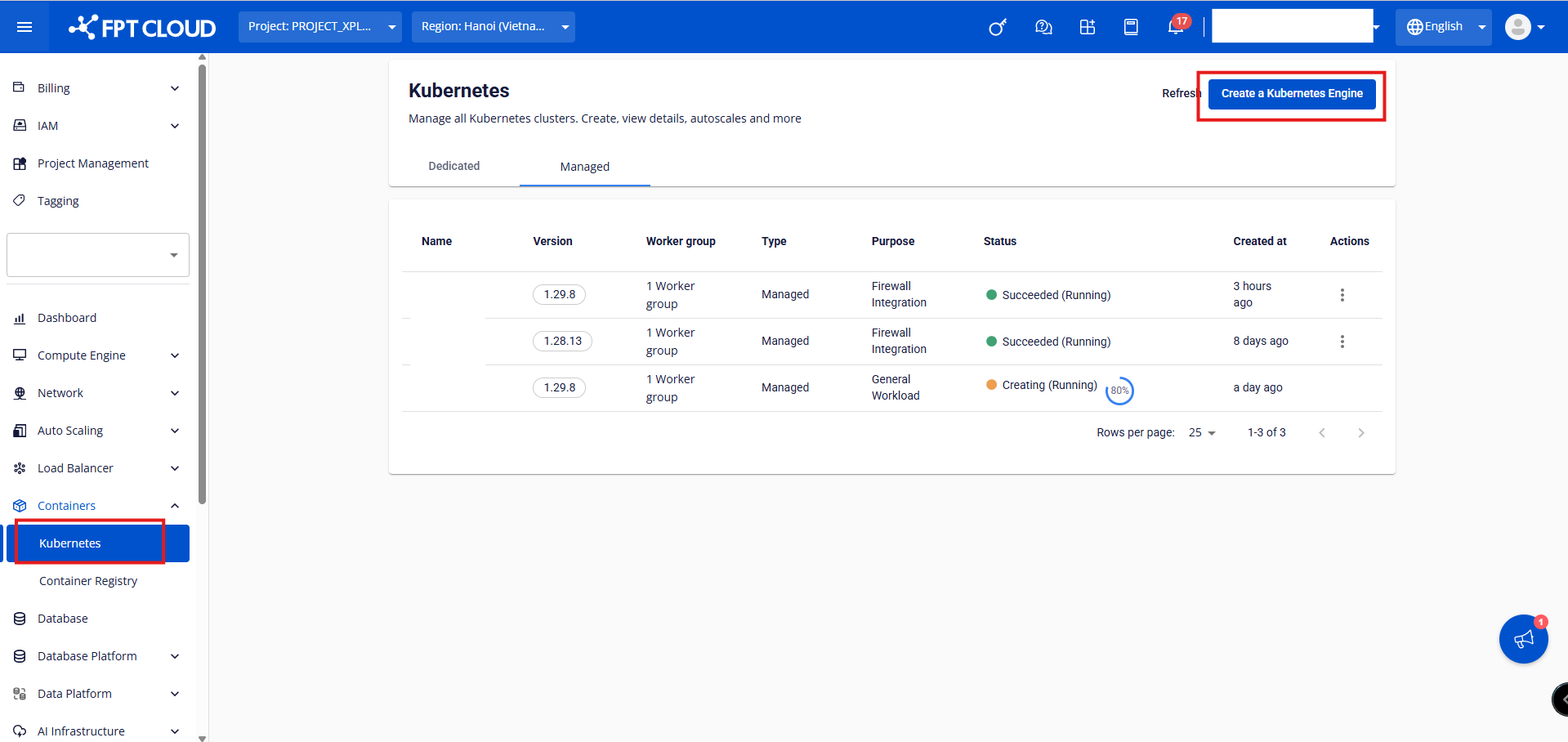
ステップ2: クラスターの基本情報を入力してボタンをクリックします。
1.1. Basics Information:
- Name: クラスター名を入力します。
- Network: KubernetesクラスターのVMをデプロイするために使用するサブネットです。
- Version: Kubernetesクラスターのバージョンを選択します。
- Cluster Endpoint Access: Kubernetesクラスターエンドポイントへのアクセス方法を選択します。
ステップ3: 必要に応じてNode Poolsを設定してボタンをクリックします。
H100カードの場合、ポータルはGPUワーカーをベースワーカーグループとして作成することをサポートしていません。ワーカーグループ2以降からGPUワーカーグループを作成してください。
-
ベースWorker Group:
- Instance Type: Generalインスタンスタイプを選択
- Type: ワーカーノードの設定(CPU & メモリ)を選択
- Container Runtime: Containerd を選択
- Policy: ワーカーノードディスクの Storage Policy(IOPSに対応)を選択
- Disk: ワーカーノードのルートディスクサイズを選択
- Scale min: k8sクラスターのワーカーノードVMインスタンスの最小数。本番環境では最低3ノードを推奨します。
- Scale max: k8sクラスター内のワーカーグループのワーカーノードVMインスタンスの最大数。
- Label: ワーカーグループにラベルを追加
-
Worker Group n:
- インスタンスタイプ: GPU を選択
- GPUタイプ: Nvidia H100 SXM5 を選択
- GPU共有設定を選択
- GPUタイプ設定(CPU / RAM / GPU RAM)を選択
- 「GPU Driver Installation Type」には Pre-install と User-install の2つのオプションがあります。
- ドライバーとは、OSがワーカーのOSとGPUと通信するためのプログラムです。ドライバーがなければOSはGPUを使用できません。
- Pre-install を選択すると、NVIDIAのGPUドライバーがクラスターに自動的に追加されます。
- User-install を選択すると、適切なドライバーバージョンを選択してGPUドライバーを手動でインストールできます。
ステップ4: Createをクリックして初期化情報を確認します。
ステップ5: Kubernetesクラスターの初期化状態を監視します。ステータスがSucceeded(Running)になったら、アプリケーションをデプロイできます。
3. GPU H200 SXM5
ステップ1: FPTポータルメニューで Containers > Kubernetes > Create a Kubernetes Engine を選択します。
ステップ2: クラスターの基本情報を入力してボタンをクリックします。
1.1. Basics Information:
- Name: クラスター名を入力します。
- Network: KubernetesクラスターのVMをデプロイするために使用するサブネットです。
- Version: Kubernetesクラスターのバージョンを選択します。
- Cluster Endpoint Access: Kubernetesクラスターエンドポイントへのアクセス方法を選択します。
- セキュリティ要件とネットワークアーキテクチャに合ったCluster Endpoint Accessモードを選択してください。
- Public & PrivateまたはPrivateを選択すると、「Allow CIDR」フィールドが表示され、アクセスを許可するIPアドレス範囲を入力できます。
ステップ3: 必要に応じてNode Poolsを設定してボタンをクリックします。
H200カードの場合、ポータルはGPUワーカーをベースワーカーグループとして作成することをサポートしていません。ワーカーグループ2以降からGPUワーカーグループを作成してください。
-
ベースWorker Group:
- Instance Type: Generalインスタンスタイプを選択
- Type: ワーカーノードの設定(CPU & メモリ)を選択
- Container Runtime: Containerd を選択
- Policy: ワーカーノードディスクの Storage Policy(IOPSに対応)を選択
- Disk: ワーカーノードのルートディスクサイズを選択
- Scale min: k8sクラスターのワーカーノードVMインスタンスの最小数。本番環境では最低3ノードを推奨します。
- Scale max: k8sクラスター内のワーカーグループのワーカーノードVMインスタンスの最大数。
- Label: ワーカーグループにラベルを追加
-
Worker Group n:
- インスタンスタイプ: GPU を選択
- GPUタイプ: Nvidia H200 SXM5 を選択
- GPU共有設定を選択
- GPUタイプ設定(CPU / RAM / GPU RAM)を選択
- 「GPU Driver Installation Type」には Pre-install と User-install の2つのオプションがあります。
- ドライバーとは、OSがワーカーのOSとGPUと通信するためのプログラムです。ドライバーがなければOSはGPUを使用できません。
- Pre-install を選択すると、NVIDIAのGPUドライバーがクラスターに自動的に追加されます。
- User-install を選択すると、適切なドライバーバージョンを選択してGPUドライバーを手動でインストールできます。
ステップ4: Createをクリックして初期化情報を確認します。
ステップ5: Kubernetesクラスターの初期化状態を監視します。ステータスがSucceeded(Running)になったら、アプリケーションをデプロイできます。