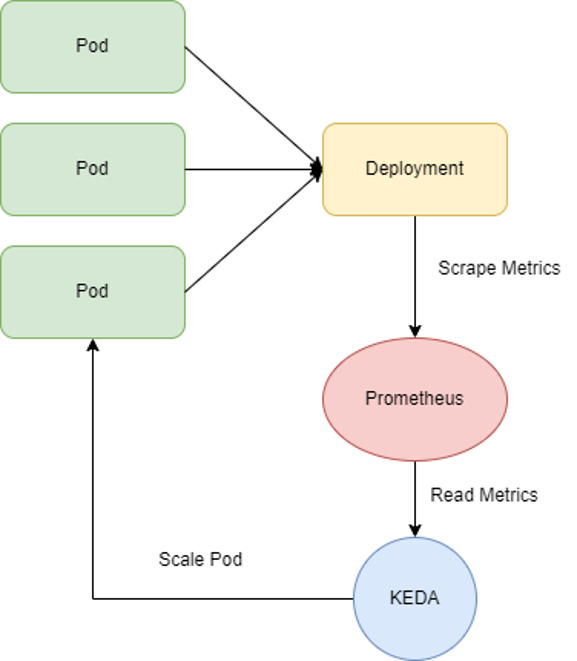
KEDAとPrometheusを使用したオートスケールの設定
前提条件
- GPUが接続されたKubernetesクラスター
- Running状態のGPUアプリケーション
- GPUカスタムメトリクスを使用したFPT Kubernetes Engine GPUのオートスケール設定の手順に従って、FPT App CatalogサービスでkubeprometheusスタックとPrometheusアダプターがすでにインストール済みであること
設定手順
ステップ1: KEDAのインストール
方法1: FPT App Catalogを使用する
FPT Cloud App Catalogサービスを選択し、fptcloud-catalogs リポジトリでKEDAを検索します。
方法2: Helmチャートを使用する
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
helm install keda kedacore/keda --namespace keda --create-namespace
KEDAのPodが正常に動作しているか確認します。
kubectl -n keda get pod
NAME READY STATUS RESTARTS AGE
pod/keda-admission-webhooks-54764ff7d5-l4tks 1/1 Running 0 3d
pod/keda-operator-567cb596fd-wx4t8 1/1 Running 0 2d23h
pod/keda-operator-metrics-apiserver-6475bf5fff-8x8bw 1/1 Running 0 2d14h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/keda-admission-webhooks ClusterIP 100.71.2.54 443/TCP 3d2h
service/keda-operator ClusterIP 100.66.228.223 9666/TCP 3d2h
service/keda-operator-metrics-apiserver ClusterIP 100.71.162.181 443/TCP,8080/TCP 3d2h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/keda-admission-webhooks 1/1 1 1 3d2h
deployment.apps/keda-operator 1/1 1 1 3d2h
deployment.apps/keda-operator-metrics-apiserver 1/1 1 1 3d2h
NAME DESIRED CURRENT READY AGE
replicaset.apps/keda-admission-webhooks-54764ff7d5 1 1 1 3d2h
replicaset.apps/keda-operator-567cb596fd 1 1 1 3d2h
replicaset.apps/keda-operator-metrics-apiserver-6475bf5fff 1 1 1 3d2h
ステップ2: PrometheusにGPUメトリクスが存在するか確認する
kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1 | jq -r . | grep DCGM
"name": "namespaces/DCGM_FI_DEV_POWER_USAGE",
"name": "namespaces/DCGM_FI_DEV_FB_USED",
"name": "namespaces/DCGM_FI_DEV_PCIE_REPLAY_COUNTER",
"name": "pods/DCGM_FI_DEV_XID_ERRORS",
"name": "namespaces/DCGM_FI_PROF_GR_ENGINE_ACTIVE",
"name": "namespaces/DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION",
"name": "pods/DCGM_FI_PROF_DRAM_ACTIVE",
"name": "jobs.batch/DCGM_FI_DEV_POWER_USAGE",
"name": "jobs.batch/DCGM_FI_DEV_SM_CLOCK",
"name": "namespaces/DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL",
"name": "pods/DCGM_FI_DEV_POWER_USAGE",
"name": "jobs.batch/DCGM_FI_DEV_MEM_CLOCK",
"name": "jobs.batch/DCGM_FI_DEV_FB_USED",
"name": "namespaces/DCGM_FI_DEV_FB_FREE",
"name": "jobs.batch/DCGM_FI_PROF_GR_ENGINE_ACTIVE",
"name": "pods/DCGM_FI_DEV_MEMORY_TEMP",
"name": "pods/DCGM_FI_DEV_FB_FREE",
"name": "pods/DCGM_FI_DEV_MEM_CLOCK",
"name": "pods/DCGM_FI_PROF_GR_ENGINE_ACTIVE",
"name": "pods/DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL",
"name": "pods/DCGM_FI_PROF_PIPE_TENSOR_ACTIVE",
"name": "jobs.batch/DCGM_FI_DEV_MEMORY_TEMP",
"name": "namespaces/DCGM_FI_DEV_MEM_CLOCK",
"name": "jobs.batch/DCGM_FI_DEV_XID_ERRORS",
"name": "namespaces/DCGM_FI_DEV_VGPU_LICENSE_STATUS",
"name": "jobs.batch/DCGM_FI_DEV_VGPU_LICENSE_STATUS",
"name": "pods/DCGM_FI_DEV_GPU_TEMP",
"name": "jobs.batch/DCGM_FI_PROF_PIPE_TENSOR_ACTIVE",
"name": "pods/DCGM_FI_DEV_PCIE_REPLAY_COUNTER",
"name": "pods/DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION",
"name": "jobs.batch/DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION",
"name": "pods/DCGM_FI_DEV_FB_USED",
"name": "pods/DCGM_FI_DEV_VGPU_LICENSE_STATUS",
"name": "namespaces/DCGM_FI_DEV_MEMORY_TEMP",
"name": "jobs.batch/DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL",
"name": "namespaces/DCGM_FI_DEV_SM_CLOCK",
"name": "namespaces/DCGM_FI_PROF_PIPE_TENSOR_ACTIVE",
"name": "namespaces/DCGM_FI_DEV_GPU_TEMP",
"name": "jobs.batch/DCGM_FI_DEV_GPU_TEMP",
"name": "namespaces/DCGM_FI_PROF_DRAM_ACTIVE",
"name": "namespaces/DCGM_FI_DEV_XID_ERRORS",
"name": "jobs.batch/DCGM_FI_DEV_FB_FREE",
"name": "pods/DCGM_FI_DEV_SM_CLOCK",
"name": "jobs.batch/DCGM_FI_DEV_PCIE_REPLAY_COUNTER",
"name": "jobs.batch/DCGM_FI_PROF_DRAM_ACTIVE",
ステップ3: アプリケーションのオートスケールを定義するScaledObjectを作成する
マニフェストの例:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: scaled-object
spec:
scaleTargetRef:
name: gpu-test
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-kube-prometheus-prometheus.prometheus.svc.cluster.local:9090
metricName: engine_active
query: sum(DCGM_FI_PROF_GR_ENGINE_ACTIVE{modelName="NVIDIA A30", container="gpu-test"}) / count(DCGM_FI_PROF_GR_ENGINE_ACTIVE{modelName="NVIDIA A30", container="gpu-test"})
threshold: '0.8'
- name: GPU Deploymentの名前 — この例では
gpu-test。 - serverAddress: Prometheusサーバーのエンドポイント — この例では
http://prometheus-kube-prometheus-prometheus.prometheus.svc.cluster.local:9090。 - query: オートスケールの判断に使用するPromQL式 — この例では
DCGM_FI_PROF_GR_ENGINE_ACTIVEの平均値。 - threshold: オートスケールをトリガーするしきい値 — この例では
0.8。
上記の例のように、DCGM_FI_PROF_GR_ENGINE_ACTIVE の平均値が 0.8 を超えるたびに、ScaledObjectは gpu-test という名前のDeploymentのPodをスケールします。
ScaledObjectを作成すると、Deploymentは自動的に0にスケールされます。これにより設定が正常に完了したことが確認できます。