KubernetesへのGPUアプリケーションのデプロイ
KubernetesはCPUリソースと同様にGPUリソースを管理・使用します。ワーカーグループに選択したGPU設定に基づいて、アプリケーションのGPUリソースを宣言します。
注意事項:
- GPUリクエストを指定せずにGPUリミットのみを指定できます(KubernetesはリミットをデフォルトのリクエストとSして使用します)。
- GPUリミットとリクエストの両方を指定できますが、両者の値は同一である必要があります。
- GPUリミットを指定せずにGPUリクエストのみを指定することはできません。
以下のコマンドでGPU設定を確認します:
kubectl get node -o json | jq '.items[].metadata.labels'
例: 以下の画像は、NVIDIA A30カードをstrategy: all-balanced、status: successで使用しているワーカーを示しています。
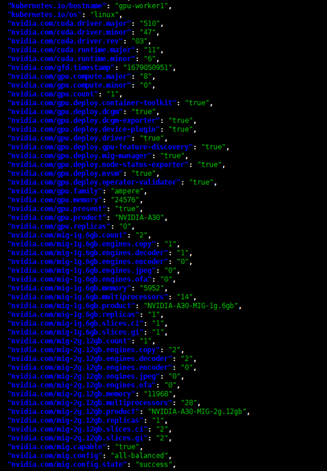
デプロイ例
1. singleストラテジーのMIG共有モード
GPUリソースは以下のように宣言します:
nvidia.com/gpu: <number>
nvidia.com/gpu: 1
GPU singleストラテジーを使用したデプロイ例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-gpu-app
spec:
replicas: 1
selector:
matchLabels:
component: gpu-app
template:
metadata:
labels:
component: gpu-app
spec:
containers:
- name: gpu-container
securityContext:
capabilities:
add:
- SYS_ADMIN
resources:
limits:
nvidia.com/gpu: 1
image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04
command: ["/bin/sh", "-c"]
args:
- while true; do /usr/bin/dcgmproftester11 --no-dcgm-validation -t 1004 -d 300; sleep 30; done
2. mixedストラテジーのMIG共有モード
GPUリソースは以下のように宣言します:
nvidia.com/<mig-profile>: <number>
nvidia.com/mig-1g.6gb: 2
GPU mixedストラテジーを使用したデプロイ例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-gpu-app
spec:
replicas: 1
selector:
matchLabels:
component: gpu-app
template:
metadata:
labels:
component: gpu-app
spec:
containers:
- name: gpu-container
securityContext:
capabilities:
add:
- SYS_ADMIN
resources:
limits:
nvidia.com/mig-1g.6gb: 1
image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04
command: ["/bin/sh", "-c"]
args:
- while true; do /usr/bin/dcgmproftester11 --no-dcgm-validation -t 1004 -d 300; sleep 30; done
3. noneストラテジー
GPUリソースは以下のように宣言します:
nvidia.com/gpu: 1
GPU noneストラテジーを使用したデプロイ例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-gpu-app
spec:
replicas: 1
selector:
matchLabels:
component: gpu-app
template:
metadata:
labels:
component: gpu-app
spec:
containers:
- name: gpu-container
securityContext:
capabilities:
add:
- SYS_ADMIN
resources:
limits:
nvidia.com/gpu: 1
image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04
command: ["/bin/sh", "-c"]
args:
- while true; do /usr/bin/dcgmproftester11 --no-dcgm-validation -t 1004 -d 300; sleep 30; done
4. MPS共有モード
GPUリソースは以下のように宣言します:
nvidia.com/gpu: <number>
nvidia.com/gpu: 1
注意: Podがリクエストできるnvidia.com/gpuリソースの最大値は1です。