GPU共有モードの使用方法
GPU共有モードにより、物理GPUを複数のコンテナで共有してGPU利用率を最適化できます。以下のGPU共有戦略がサポートされています。
| Multi-instance GPU | GPU time-sharing | NVIDIA MPS | |
|---|---|---|---|
| 概要 | GPUを分割して複数のコンテナで共有 | 各コンテナが時間スライスでGPUを使用 | コンテナが並列でGPUを使用 |
| 分離 | GPUは最大7つのインスタンスに分割され、各インスタンスは専用のコンピューティング、メモリ、帯域幅を持ちます。各パーティションは完全に独立しています。 | 各コンテナはGPU上で実行されるプロセス間のコンテキストスイッチングによって物理GPUの全容量にアクセスします。ただし、time-sharingは共有ジョブ間のメモリ制限を強制せず、共有アクセスのための頻繁なコンテキストスイッチングによりオーバーヘッドが生じる場合があります。 | NVIDIA MPSはリソース分離が限定的ですが、GPUタイプや最大共有ユニット数など他の面では柔軟性が高く、リソース割り当てを簡略化します。 |
| 適したワークロード | 並列で実行され、一定のレジリエンスとQoSが必要なワークロードに推奨されます。例えば、AI推論ワークロードを実行する場合、multi-instance GPUにより複数の推論クエリを同時に実行して迅速なレスポンスを提供できます。 | アイドル期間のある突発的でインタラクティブなワークロードに推奨されます。これらのワークロードは専用GPUでは費用対効果が低いです。time-sharingを使用することで、アクティブフェーズ時にGPUへ素早くアクセスできます。 | MPSは小さなジョブのバッチ処理に推奨されます。MPSはGPUのスループットと同時使用を最大化します。MPS対応ワークロードはメモリ保護とエラー封じ込めの制限を許容する必要があります。 |
A. Multi-instance GPU(MIG)
Multi-instance GPUは、GPUを最大7つの独立したパーティションに分割できる機能です。これらのGPUパーティションはMIGインスタンスと呼ばれ、コンピューティング能力、帯域幅、メモリの面で完全に独立しています。
当社のGPU KubernetesサービスはGPU A100で以下のMIGプロファイルをサポートしています。
| No. | GPU A100プロファイル | 戦略 | インスタンス数 | インスタンスリソース |
|---|---|---|---|---|
| 1 | all-1g.10gb | single | 7 | 1g.10gb |
| 2 | all-1g.20gb | single | 4 | 4g.20gb |
| 3 | all-2g.20gb | single | 3 | 2g.20gb |
| 4 | all-3g.40gb | single | 2 | 3g.40gb |
| 5 | all-4g.40gb | single | 1 | 4g.40gb |
| 6 | all-balanced | mixed | 2 / 1 / 1 | 1g.10gb / 2g.20gb / 3g.40gb |
| 7 | none with operator | none | 0 | 0(GPU全体) |
| 8 | none | none | 0 | 0 |
GPU A30で以下のMIGプロファイルをサポートしています。
| No. | GPU A30プロファイル | 戦略 | インスタンス数 | インスタンスリソース |
|---|---|---|---|---|
| 1 | all-1g.6gb | single | 4 | 1g.6gb |
| 2 | all-2g.12gb | single | 2 | 2g.10gb |
| 3 | all-4g.24gb | single | 1 | 4g.24gb |
| 4 | all-balanced | mixed | 2 / 1 | 1g.6gb / 2g.12gb |
例: strategy single: all-1g.6gb を選択した場合、ワーカー上のGPU A30カードは4つのMIGデバイスに分割され、各デバイスは物理GPUの1/4のGPUリソースと6 GBのGPU RAMを持ちます。
注意事項:
- MIG設定はワーカーに接続されているすべてのカードに適用されます。
- 同じクラスター内のすべてのワーカーグループのMIG戦略は同じタイプ(single / mixed / none)である必要があります。
- 「none with Operator」戦略では、PodはGPU全体のリソースを含む1つのGPUデバイスを使用できます。
- 「none」戦略では、GPUはすでにマシンに接続されています。ユーザーは希望する設定でGPU OperatorまたはGPUデバイスプラグインを手動でデプロイできます。この戦略を使用する前に、GPU共有の基本知識を十分に習得することを強くお勧めします。
B. GPU KubernetesサービスでのMIGの設定
ワーカーグループGPUの初期化ステップで、インターフェイスからMIG共有モードプロファイルを選択でき、当社のGPU Kubernetesサービスが設定を行います。
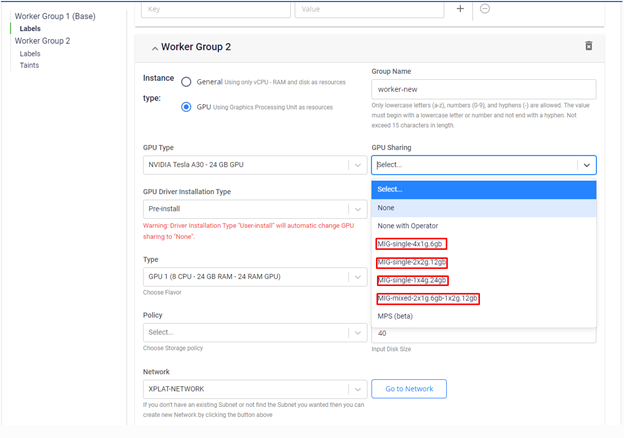
注意事項:
- 「MIG single」タイプのプロファイルを選択すると、後続のワーカーグループは「MIG single」プロファイルの共有モードのみ選択できます。「MIG mixed」、「None」、「None with Operator」も同様です。
- 共有モード「None」は、GPU Kubernetesクラスターの完全な制御をユーザーに委ねることを意味します。GPU OperatorまたはNVIDIAデバイスプラグインを手動でインストールして必要な共有モードを実行できます。
- 共有モード「None with operator」は、当社がGPU Operatorを管理することを意味します。ただし、1つのGPUは一度に最大1つのコンテナにのみ割り当てられます。
MIGの確認:
ポータルがクラスターのステータスをsuccessと報告した後、以下のコマンドでGPUノードのGPUリソースを確認できます。
kubectl describe nodes
出力:
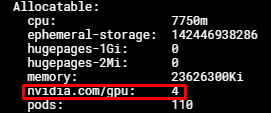
この時点で、Podに最大4つの nvidia.com/gpu リソースをリクエストできます。各 nvidia.com/gpu リソースは物理GPUのコンピューティング能力とメモリの1/4に相当します。
ノードが2つのGPUを使用している場合、8つの nvidia.com/gpu リソースが表示されます。
また、MIGとtime slicing(サポート済み)やMPS(未サポート)などの他のGPU共有戦略を組み合わせてGPU利用率を最大化することもできます。
C. Multi-Process Service(MPS)
- MPSはNVIDIA GPUの機能で、複数のコンテナが同じ物理GPUを共有できます。
- MPSはGPUリソースの分割においてMIGよりも優れており、最大48のコンテナが同時にGPUを使用できます。
- MPSはNVIDIAのCUDA向けMulti-Process Service機能に基づいており、複数のCUDAアプリケーションが1つのGPU上で同時に実行できます。
- MPSを使用すると、GPUのレプリカ数を事前に定義できます。この値は1つのGPUにアクセスできるコンテナの最大数を示します。
- また、コンテナ内に以下の環境変数を設定することで、各コンテナのGPUリソースを制限できます。
CUDA_MPS_ACTIVE_THREAD_PERCENTAGECUDA_MPS_PINNED_DEVICE_MEM_LIMIT
- MPSの動作の詳細については、https://docs.nvidia.com/deploy/mps/ を参照してください。
FPTCloud K8s GPUサービスでのMPS設定:
ワーカーグループの初期化時にGPUワーカーグループにMPSを使用するよう設定できます。
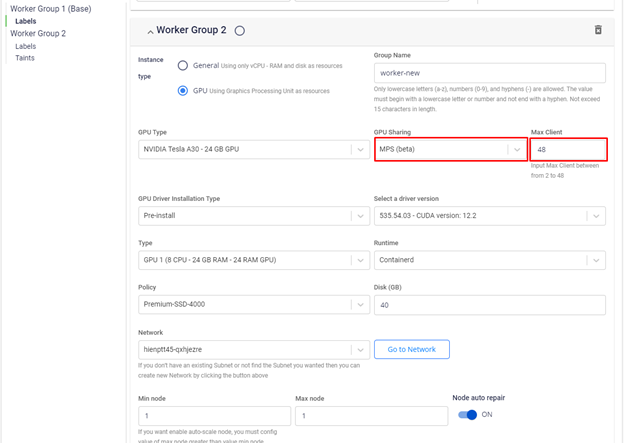
この設定では、GPUは48の部分に「分割」され、各部分は元の物理GPUの1/48のコンピューティング能力とメモリを持ちます。
MPSの確認:
GPUノードのMPS設定を確認するには、以下のコマンドを実行します。
kubectl describe nodes $NODE_NAME
出力:
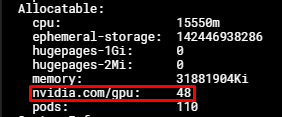
この時点で、Podに最大48つの nvidia.com/gpu リソースをリクエストできます。各 nvidia.com/gpu リソースは物理GPUのコンピューティング能力とメモリの1/48に相当します。
ノードが2つのGPUを使用している場合、96つの nvidia.com/gpu リソースが表示されます。
重要な注意事項:
- コンテナがリクエストする
nvidia.com/gpuリソースは1でなければなりません。 - クライアントの最大数は48、最小数は2で、物理GPUリソースは最大クライアント数で均等に分割されます。
- MPSの共有モードでエラーが発生しないよう、各コンテナは1つのプロセスを実行します。
- ワークロードデプロイメントマニフェストに
hostIPC: trueフィールドが必要です。 - MPSにはエラー封じ込めとワークロード分離に関する制限があります。使用前に十分に検討してください。
D. Time slicing
- Time slicingはプリミティブなGPU共有機能で、各プロセス/コンテナが均等な時間スライスでGPUを使用します。
- Time slicingはCPUスタイルのコンテキストスイッチングメカニズムによってGPU共有を実装します。各プロセス/コンテナは、別のプロセスがGPUを使用しているときにコンテキストが保存されます。
- Time slicingはMPSのような並列GPU共有をサポートしていません。
GPU KubernetesサービスでのTime slicingの設定:
Time slicingはプリミティブなGPU共有機能で、すべてのMIG共有モード(MIG-mixedプロファイルを除く)と「None with Operator」モードで使用できます。
ワーカーグループGPUの初期化ステップで、time slicingとMIGを組み合わせるか、MIGモードが有効なGPUでtime slicingを使用するかを選択でき、当社が設定を行います。
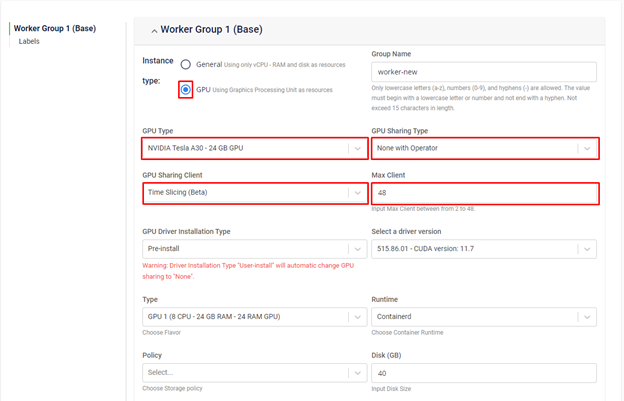
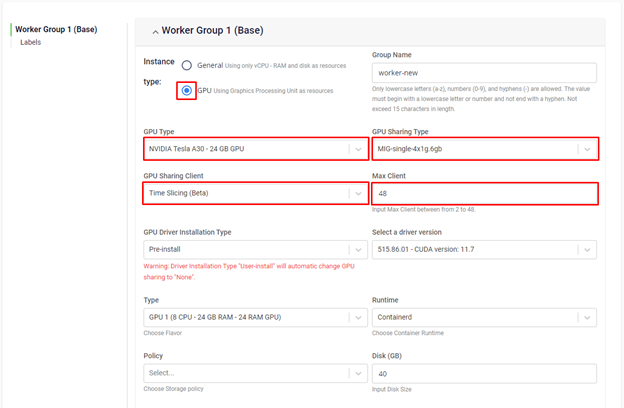
Time slicingの確認:
GPUノードのtime slicing設定を確認するには、以下のコマンドを実行します。
kubectl describe nodes $NODE_NAME
出力:
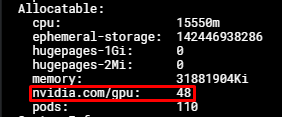
この時点で、Podに最大48つの nvidia.com/gpu リソースをリクエストできます。ただしMPSとは異なり、各Podが消費できるリソース量に制限がないため、メモリ不足(OOM)が発生する可能性があります。
MIGモードを使用している場合、nvidia.com/gpu リソース数はMIGインスタンス数に定義したtime slicingの最大クライアント数を掛けた値になります。例えば、MIGモード 2x2g.12gb を使用し、time slicingクライアント数が48の場合、96の nvidia.com/gpu リソースが表示されます。
重要な注意事項:
- コンテナがリクエストする
nvidia.com/gpuリソースは1以上でも構いません。ただし、1より多くのnvidia.com/gpuをリクエストしても、コンテナがより多くのリソースにアクセスできるわけではありません。 - Time slicingを使用する場合、コンテナのコンピューティングリソースとメモリ使用量は制限されません。
- クライアントの最大数は48、最小数は2です。
- 各コンテナは1つのプロセスを実行します。
- OOMエラーによるGPU動作の中断を防ぐため、コンテナが必要とするGPUリソース量を明確に定義してください。