GPUでのAutoscalerの使用方法
コンテナレベルのオートスケーリング
Horizontal Pod Autoscaler(HPA)は、アプリケーションの需要に合わせてワークロードリソース(DeploymentやStatefulSetなど)を自動的に更新してスケールします。基本的に、KubernetesアプリケーションのワークロードがKubernetes上で増加すると、HPAはリソース要件を満たすためにより多くのPodをデプロイします。負荷が減少し、Pod数が設定した最小値を上回っている場合は、HPAがワークロードリソース(Deployment、StatefulSetなど)を削減し、Pod数を減らします。GPU用HPAはDCGMカスタムメトリクスを使用して、GPUアプリケーションのワークロードに基づいてPodを増減監視します。
GPUアプリケーション用にHPAを設定するには、以下の設定を参考にしてください。
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: my-gpu-app
spec:
maxReplicas: 3 # 適宜更新してください
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1beta1
kind: Deployment
name: my-gpu-app # オートスケール対象のDeploymentのラベルを追加
metrics:
- type: Pods # GPUに基づいてPodをスケール
pods:
metric:
name: DCGM_FI_PROF_GR_ENGINE_ACTIVE # 適切なDCGMメトリクスを追加
target:
type: AverageValue
averageValue: 0.8 # 要件に応じてしきい値を設定
詳細については、NVIDIAのDCGMメトリクスに関するドキュメントを参照してください。
GPUアプリケーションのHPAが初期化されたことを確認するには、以下のコマンドを実行します。

ノードレベルのオートスケーリング
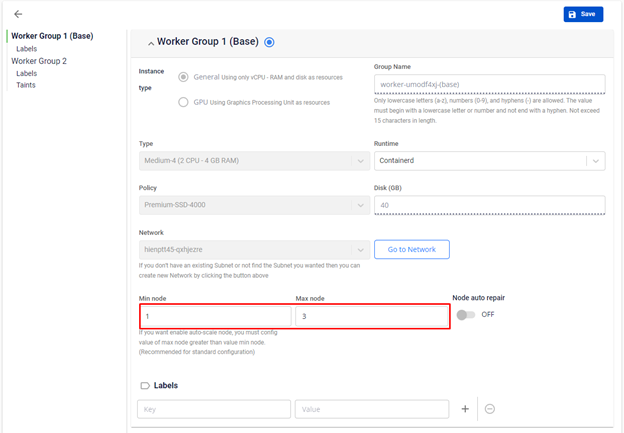
通常のCluster Autoscalerと同様に、KubernetesクラスターはGPU使用量の需要に基づいて、ワーカーグループ内のワーカーノードを自動的に増減します。そのワーカーグループで動作するアプリケーションが既存のワーカーノードから十分なGPUリソースを提供されない場合、新しいワーカーが自動的にワーカーグループに追加されます。リソース不足でPendingになっているPodは、スケールアップ後に新しいワーカーノードによって処理されます。Cluster Autoscalerは、使用率がしきい値(デフォルト50%)を下回るノードも自動的に削除します。
ワーカーグループのノード数設定はFPTCloudポータルで以下のように定義されます。
参照: FPT Cloud Managed Kubernetes Autoscaler