Using Autoscaler with GPU
Container-level autoscaling
Horizontal Pod Autoscaler (HPA) automatically updates workload resources (such as Deployments or StatefulSets) to scale them according to application demand. In practice, when a Kubernetes application workload increases, HPA deploys more pods to meet resource requirements. If the load decreases and the number of pods is above the configured minimum, HPA reduces the workload resource (Deployment, StatefulSet, or similar), meaning it reduces the number of pods. GPU HPA uses DCGM custom metrics to monitor and scale pods up or down based on the GPU application workload.
To configure HPA for a GPU application, refer to the following configuration:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: my-gpu-app
spec:
maxReplicas: 3 # Update this accordingly
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1beta1
kind: Deployment
name: my-gpu-app # Add label from Deployment we need to autoscale
metrics:
- type: Pods # scale pod based on gpu
pods:
metric:
name: DCGM_FI_PROF_GR_ENGINE_ACTIVE # Add the DCGM metric here accordingly
target:
type: AverageValue
averageValue: 0.8 # Set the threshold value as per the requirement
For further reference, see the NVIDIA documentation on DCGM metrics.
To check that the HPA has been initialized for the GPU application, run:

Node-level autoscaling
Like standard Cluster Autoscaler, the Kubernetes cluster automatically scales worker nodes up or down within a worker group based on GPU usage demand. It automatically adds new workers to a worker group when the application running in that group cannot be served with sufficient GPU resources from the existing worker nodes. Pending pods caused by insufficient node resources will be served by new worker nodes after scaling up. Cluster Autoscaler also automatically removes nodes whose utilization is below the threshold (default 50%).
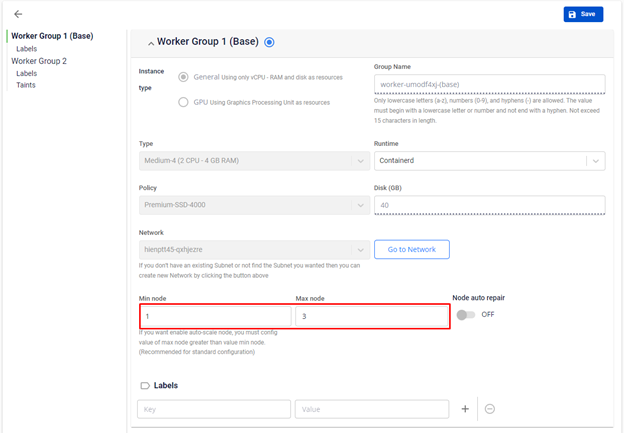
Worker group node count configuration is defined on the FPTCloud Portal as shown below:
See also: FPT Cloud Managed Kubernetes Autoscaler