データベースの作成
Database Provisioning 機能により、手動でのインフラ設定なしに FPT Database Engine プラットフォーム上でさまざまなデータベースエンジンを迅速にデプロイできます。データベースクラスターのプロビジョニングには、エンジンタイプ、ネットワーク、クラスター識別情報、およびバックアップや自動スケーリングなどのオプションサービスの構成情報を入力します。このガイドでは、複数ステップのプロセスについて説明します。
ステップ 1:データベース作成ページを開く
作成するデータベースの種類に対応する Database List ページにアクセスし(詳細はデータベース一覧の表示セクションを参照)、Create a Database Engine または Create を選択して新しいデータベースのプロビジョニングを開始します。Create new database ページが開き、FPT Database Engine 環境で新しいデータベースを定義してデプロイするための構成オプションが提供されます。プロビジョニングの進行は次の 3 ステップで構成されます:
- ステップ 1 – データベース構成
- ステップ 2 – 追加サービス構成
- ステップ 3 – 確認 & 作成
ステップ 2:データベース構成を定義する
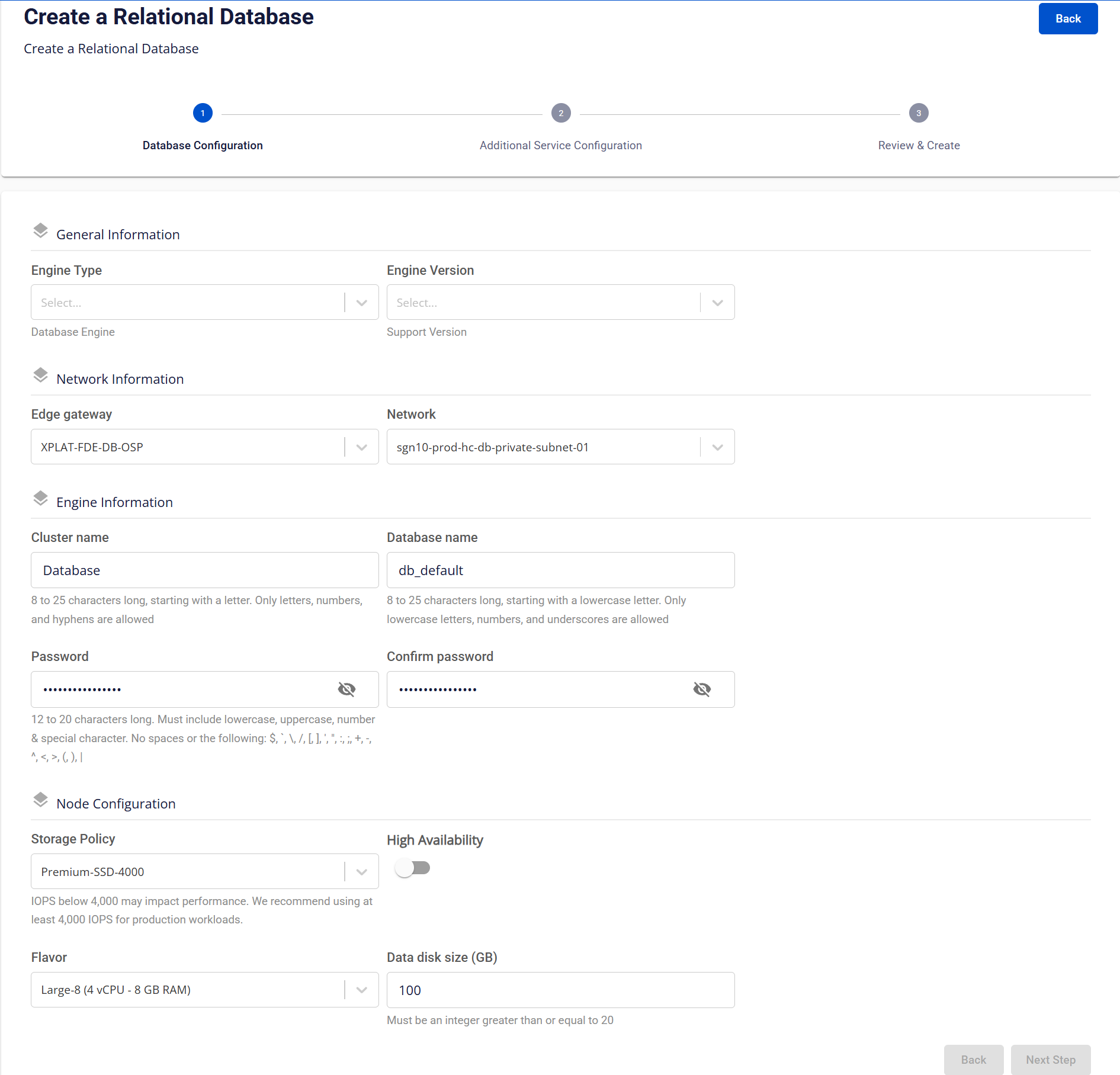
この画面はデータベースプロビジョニングワークフローの最初のステップです。エンジン選択、ネットワーク、認証情報、コンピュート/ストレージ構成などのデータベースの主要パラメータを定義するために使用されます。選択したエンジンにより、一部の情報フィールドが異なる場合があります。 画面上のフィールドの説明:
| 1. General Information セクション |
|---|
| フィールド |
| Engine Type |
- Relational Databases は次の値を表示します:"PostgreSQL"、"MySQL"、"MariaDB"、"SQL Server"
- NoSQL は次の値を表示します:"MongoDB"、"Cassandra"、"Redis"
- Search Engine は次の値を表示します:"OpenSearch"
- Data Streaming は次の値を表示します:"Kafka"
- Time Series Database は次の値を表示します:"TimescaleDB"
- OLAP は次の値を表示します:"Clickhouse"
|
| Edition | エンジンエディションを選択します:"Enterprise"、"Standard"、"Web"。
このフィールドはエンジンタイプが "SQL Server" の場合にのみ表示されます。 |
| Engine Version | Database Engine Version Policy に基づいてサポートされているエンジンバージョンを選択します。 |
|
| 2. Network Information セクション |
| フィールド | 説明 |
| Edge Gateway | データベースと他のシステム間のネットワークトラフィックをルーティングする Edge Gateway を選択します。 |
| Network | データベースインスタンスをデプロイする Network/Subnet を選択します。これによりアクセス範囲とネットワーク分離が定義されます。 |
| 3. Engine Information セクション |
| フィールド | 説明 |
| Cluster Name | データベースクラスターの論理名。名前は 8 ~ 25 文字で、英字で始まり、英字、数字、ハイフン (-) のみを含む必要があります。 |
| Database Name | クラスター内に作成されるデフォルトデータベース名。名前は 8 ~ 25 文字で、小文字で始まり、小文字、数字、アンダースコア () のみを含む必要があります。
このフィールドは Redis または Kafka エンジンタイプの場合は表示されません。 |
| VHost Name | クラスター内に作成されるデフォルトの VHost 名。名前は 8 ~ 25 文字で、小文字で始まり、小文字、数字、アンダースコア () のみを含む必要があります。
このフィールドはエンジンタイプが RabbitMQ の場合にのみ表示されます。 |
| Password/ Confirm Password | データベース管理者アカウントのパスワード。パスワードは 12 ~ 20 文字で、大文字、小文字、数字、および特殊文字を含む必要があります。
スペースおよび次の特殊文字は使用できません: / \ " ' < > ? % ; : $ ! [ ] { } ( ) , & + |
| 4. Node Configuration セクション |
| フィールド | 説明 |
| Storage Policy | ストレージパフォーマンス (IOPS) を定義する Storage Policy を選択します。本番環境ではパフォーマンスと安定性を確保するため IOPS ≥ 4,000 を選択することをお勧めします。 |
| High Availability | High Availability (HA) を有効にして、自動フェイルオーバーを備えたマルチノードクラスターをデプロイします。
このフィールドは Cassandra エンジンタイプの場合は表示されません。 ⚠️ ClickHouse Engine で HA を使用する際の重要な注意事項:- HA を有効にした ClickHouse database cluster を作成すると、サービスは各シャードのレプリカを自動的に作成します。ただし、レプリケーション機能を使用するには、ユーザーがレプリケーションをサポートするテーブルを作成する必要があります。詳細情報は、ClickHouse 公式ドキュメント Replicated* table engines | ClickHouse Doc を参照してください。
- レプリケーション は MergeTree ファミリーのテーブルでのみサポートされ、次のテーブルタイプを含みます:
- ReplicatedMergeTree
- ReplicatedSummingMergeTree
- ReplicatedReplacingMergeTree
- ReplicatedAggregatingMergeTree
- ReplicatedCollapsingMergeTree
- ReplicatedVersionedCollapsingMergeTree
- ReplicatedGraphiteMergeTree
- レプリケーション はサーバーレベルではなく テーブルレベル で動作します。つまり、レプリケートされたテーブルとレプリケートされていないテーブルが同じサーバー上で共存できます。
- レプリケーションはシャーディングから独立しています。各シャードは独自の独立したレプリケーションメカニズムを持ちます。例えば、ユーザーが MergeTree テーブル(ReplicatedMergeTree ではない)を作成した場合、そのテーブルはレプリケートされず、データは書き込まれたノードにのみ存在します。
|
| Number Of Nodes | データベースクラスターのノード数を選択します。
このフィールドはエンジンタイプが Cassandra の場合にのみ表示されます。 |
| Flavor | ノードごとのコンピュートリソース (vCPU、RAM) を定義する Flavor を選択します。 |
| Data Disk Size (GB) | データベースに割り当てられるデータディスクサイズ。サイズは GB 単位で測定され、最小値は 20 GB です。 |
必要な情報をすべて入力したら、Next Step をクリックして関連サービスの構成に進みます。
ステップ 3:追加サービスの構成
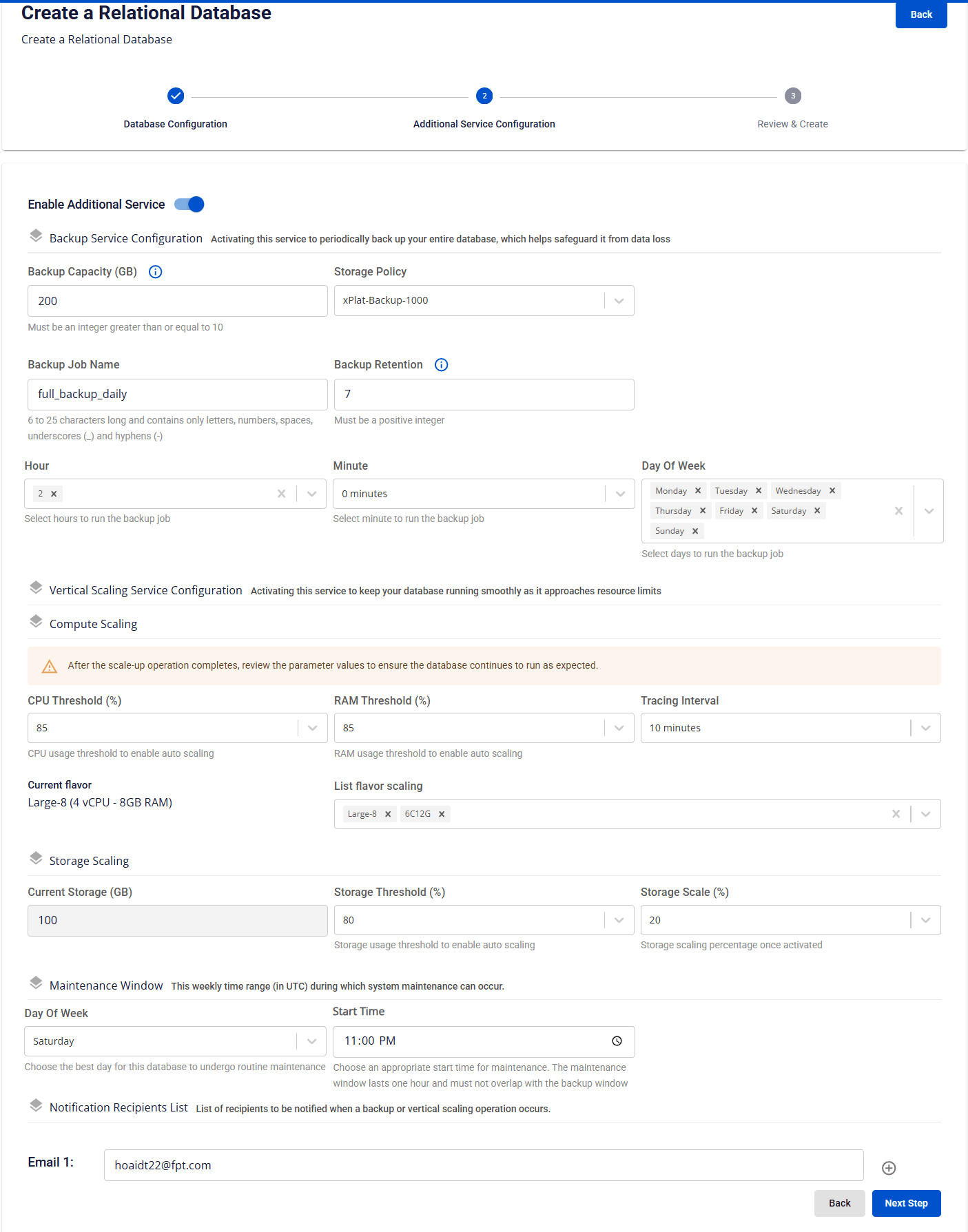
この画面では、可用性、スケーラビリティ、および運用可視性を向上させるため、バックアップ、自動スケーリング、通知などのデータベースクラスターのオプションマネージドサービスを構成できます。 データ保護、安定性、およびシステムの継続的な運用を確保するため、データベース作成時に Backup および Auto Scaling サービスを有効にすることをお勧めします。 画面上のフィールドの説明:
- Enable Additional Service :バックアップと自動スケーリングを含むデータベースクラスターのアドオンサービスを有効または無効にします。このフィールドが無効な場合、データベースクラスターはこれらのサービスなしで作成されます。クラスターが正常に作成された後にアドオンサービスを有効にできます。
- Backup Service Configuration :このサービスを有効にすると、データ損失から保護するための定期的なフルデータベースバックアップが有効になります。必須フィールドは次のとおりです:
| フィールド | 説明 |
|---|---|
| Backup Capacity (GB) | バックアップ用に割り当てられるストレージ容量。サイズは GB 単位で測定され、最小値は 10 GB です。 |
| Storage Policy | パフォーマンスと耐久性の特性を定義するバックアップストレージポリシー。 |
| Backup Job Name | バックアップジョブの論理名。名前は 6 ~ 25 文字で、英字、数字、スペース、ハイフン (-)、アンダースコア (_) のみを含む必要があります。 |
| Backup Retention | 保持するフルデータベースバックアップの数。バックアップ数がこの制限を超えると、最も古いバックアップが自動的に削除されます。 |
| Hour / Minute / Day of Week | 定期バックアップスケジュールを設定します: |
- Hour:バックアップ実行時間。
- Minute:バックアップ実行分。
- Day of Week:バックアップ実行日。
警告 :Kafka エンジンの場合、バックアップを実行すると一時的な中断が発生する可能性があります。サービスへの影響を最小限に抑えるため、オフピーク時にバックアップをスケジュールする必要があります。 |
- Vertical Scaling Service Configuration: このサービスを有効にすると、使用量のしきい値を超えた場合にシステムがコンピュートまたはストレージリソースを自動的にスケーリングできます。必須フィールドは次のとおりです:
| 1. Compute Scaling セクション |
|---|
| フィールド |
| CPU Threshold (%) |
| RAM Threshold (%) |
| Tracing Interval |
| Current Flavor |
| List Flavor Scaling |
| 2. Storage Scaling セクション |
| フィールド |
| Current Storage (GB) |
| Storage Threshold (%) |
| Storage Scale (%) |
- Maintenance Window :システムがメンテナンス活動を実行することを許可される時間帯を定義します:
- Day of Week :メンテナンスを実行する曜日。利用可能なオプションは "Monday" から "Sunday" までです。
- Start Time :選択された日にメンテナンスの開始が許可される時刻。メンテナンス期間:構成された Start Time から 1 時間。
- Notification Recipients List :バックアップまたはスケーリングイベントが発生したときに通知を受信するメールアドレスのリストを入力します。"+" ボタンをクリックして新しいメールをリストに追加することで、複数のメールを追加できます。
必要な情報をすべて入力したら、Next Step をクリックして確認ステップに進み、データベース作成を確定します。
ステップ 4:確認 & 作成
ユーザーは作成を確定する前に、データベースのすべての構成設定を確認する必要があります:
- 変更を行うには、Back をクリックして前のステップに戻り、情報を更新します。
- 情報が正しい場合は、Create をクリックしてデータベースクラスターの作成を確定します。
確認後:
- システムはリソースをチェックし、作成通知を表示し、提供された構成に基づいて新しいデータベースクラスターのデプロイを開始します。
- ユーザーはデータベース一覧にリダイレクトされ、新しく作成されたデータベースが Processing ステータスで最上部に表示されます。
作成プロセスは通常 5 ~ 7 分かかります。正常に完了すると、データベースは Running ステータスに遷移します。注意 :データベースの作成に失敗した場合は、失敗したデータベースを削除してから再作成してください。 新しく作成されたデータベースに接続するには、「データベースへの接続」セクションを参照してください。 データベースを操作するには、「データベース操作」セクションを参照してください。