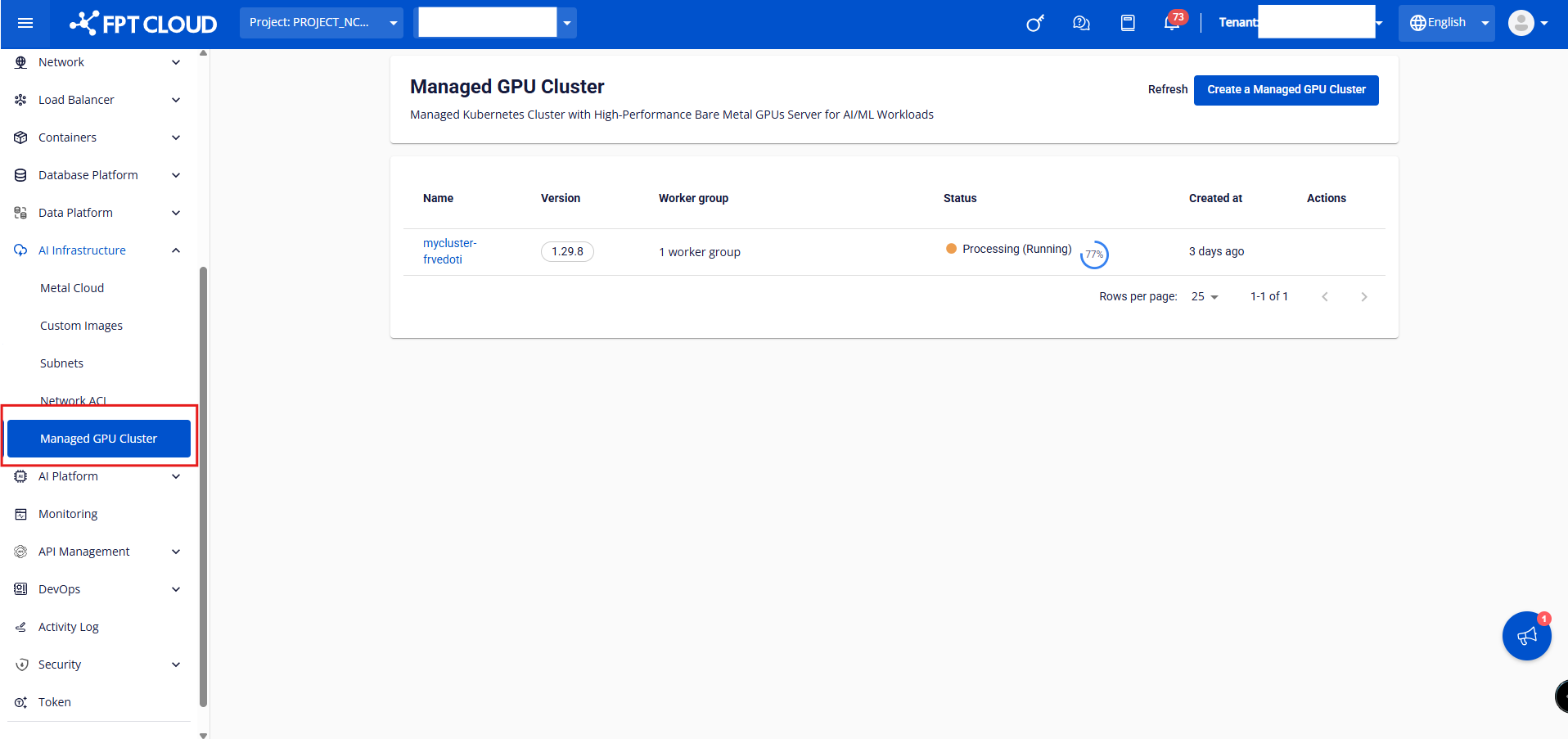
Create a new Managed GPU Cluster
Note:
Prerequisites for this operation:
- The Metal Cloud (Bare Metal HPC) quota must be sufficient to meet the desired cluster size.
- At least one BM server network.
- At least one network for the Load Balancer.
Step 1: In the FPT Portal menu, select AI Infrastructure > Managed GPU Cluster > Create a Managed GPU Cluster.
Step 2: Enter information on the General Information tab, then click Next.
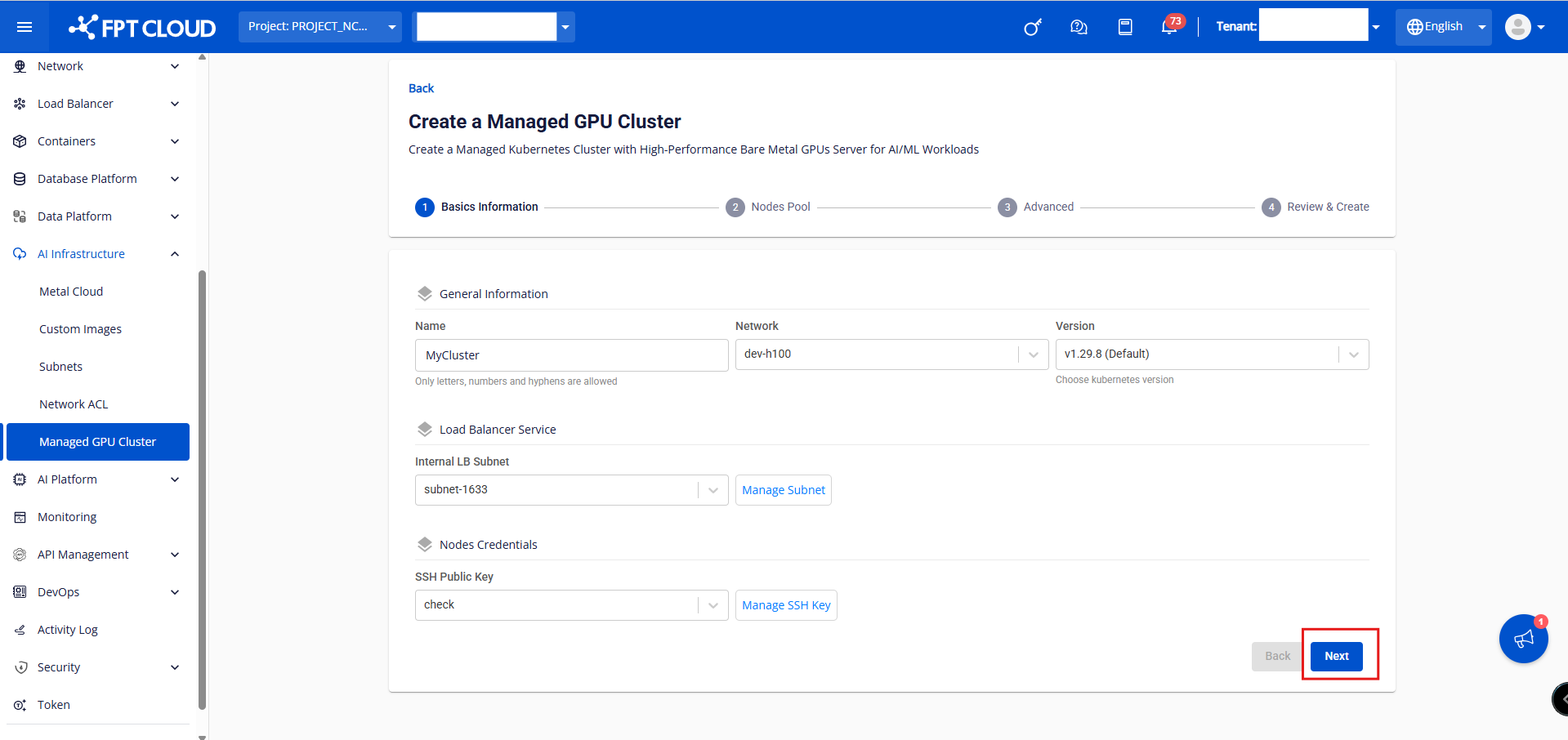
- General Information:
• Name: Enter the cluster name. Each cluster name must be unique and follow the naming rules.
• Network: Select from the subnet range created for the Bare Metal GPU Servers.
• Version: Select the Kubernetes version appropriate for your application.
• Internal LB Subnet: Configure the private IP range for the Load Balancer service type.
• SSH Public Key: SSH key for accessing Worker nodes in the cluster.
Step 3: Enter information on the Nodes Pool tab, then click Next.
Key points when creating a Managed GPU Cluster:
- Managed GPU Cluster manages Worker nodes through Worker Groups — a group of Worker nodes with the same configuration. Users can assign Worker Groups for different applications. The system requires at least one Worker Group (Base), which cannot be deleted.
- In the Worker Group configuration section, users can assign labels to the desired Worker Group. These labels will be applied to all Worker nodes in the group. Users can add or remove labels, and edit the key/value of existing labels. Labels help users easily deploy applications on specific Worker Groups as needed.
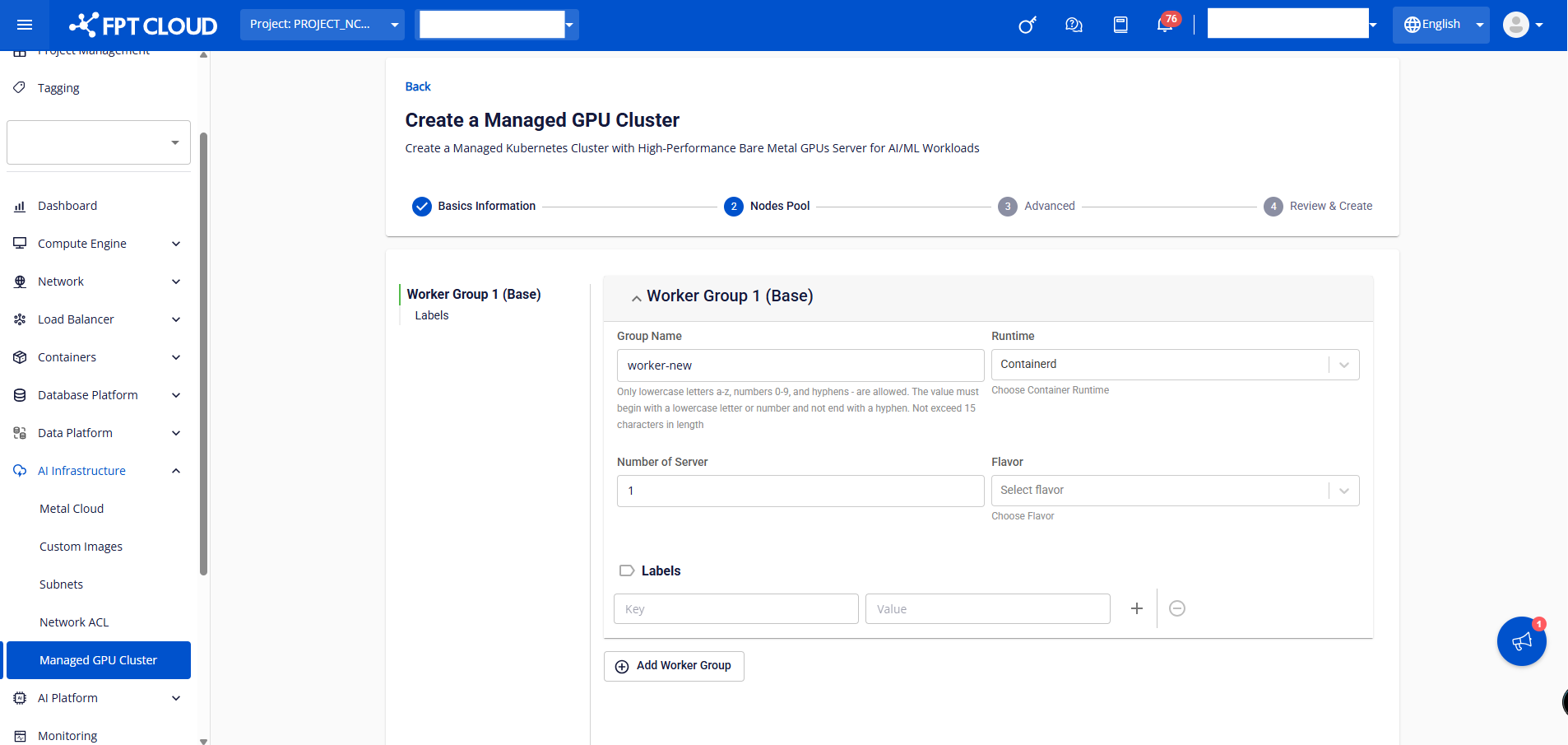
➤ Worker group 1 (Base):
• Group Name: Enter a name to identify the Worker Group.
• Runtime: Select the container runtime. Currently only Containerd is supported.
• Number of Server: The number of Metal Cloud Servers to run as Workers in the cluster.
• Flavor: The Metal Cloud GPU server flavor type; defaults to H100.
• Label: Assign Kubernetes labels to all Workers in the Worker Group.
Users can add additional worker groups when initializing the K8s cluster by clicking ADD WORKER GROUP.
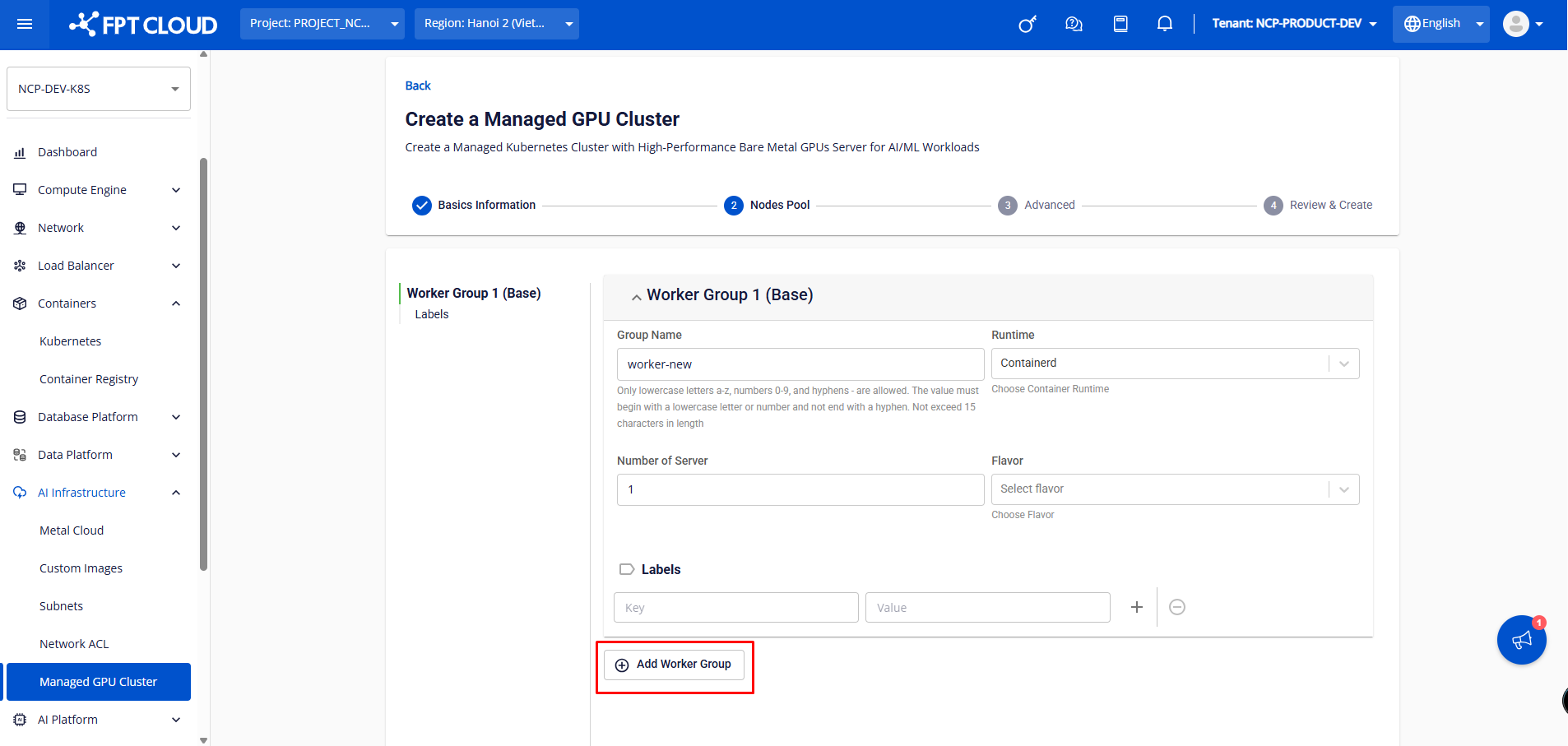
From Worker Group 2 onwards, users can configure taints for worker groups to schedule applications on specific worker nodes. Taints can also be added, removed, and edited easily.
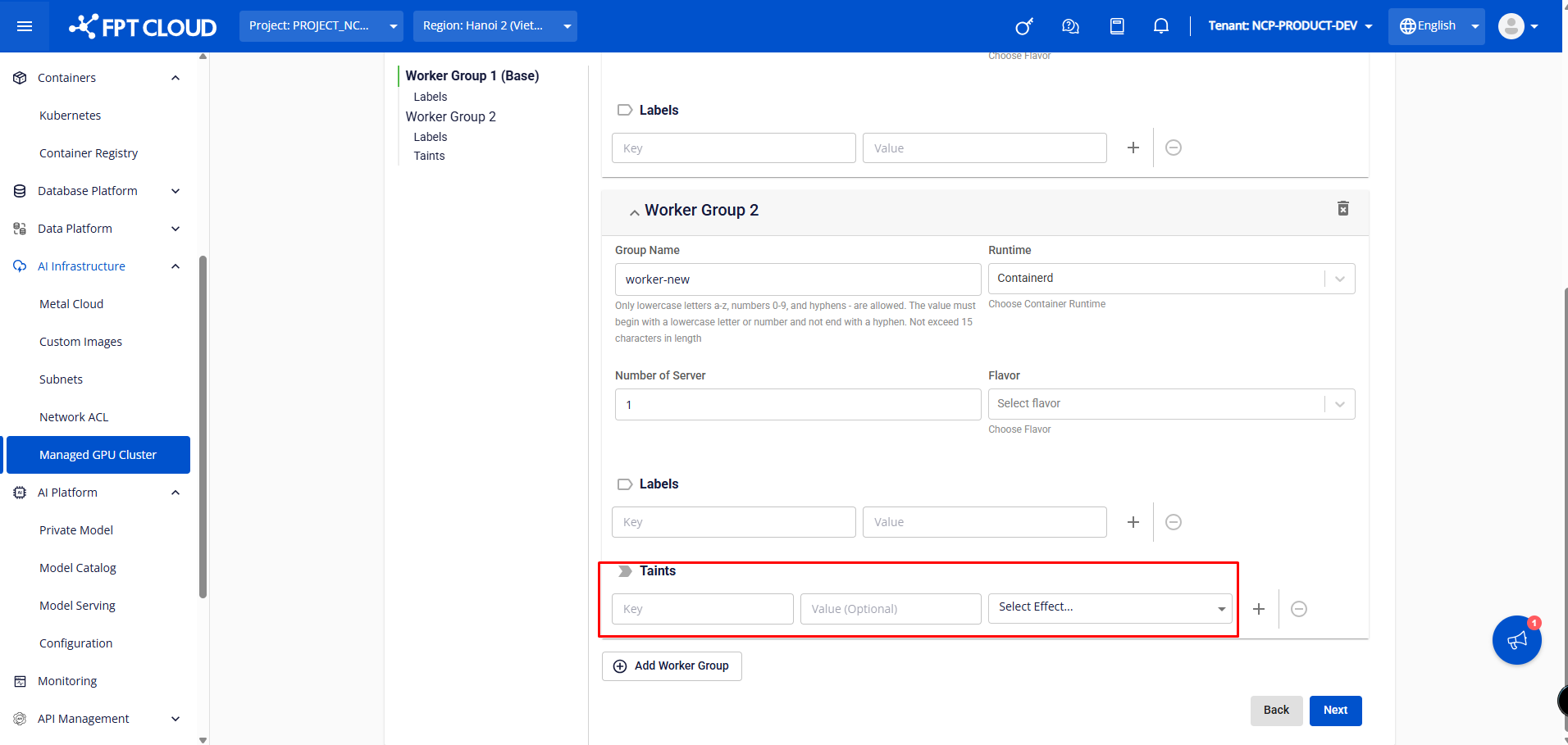
Note: When a user configures labels/taints for a worker group on the Unify Portal, they cannot delete labels/taints for nodes in that worker group using kubectl (the system will automatically re-apply the labels/taints according to the Unify Portal configuration). Labels/taints must be removed from the Unify Portal instead.
➤ Worker Group n:
Users can add additional Worker Groups when initializing the K8s cluster by clicking ADD WORKER GROUP.
From Worker Group 2 onwards, users can configure taints for Worker Groups to schedule applications on specific Worker nodes. Taints can also be added, removed, and edited easily.
Learn more about Taints here.
Note: When a user configures labels/taints for a Worker Group on the Portal, they cannot delete labels/taints for nodes in that Worker Group using kubectl (the system will automatically re-apply the labels/taints according to the Portal configuration). Labels/taints must be removed from the Portal instead.
Step 4: The Advanced section contains advanced settings.
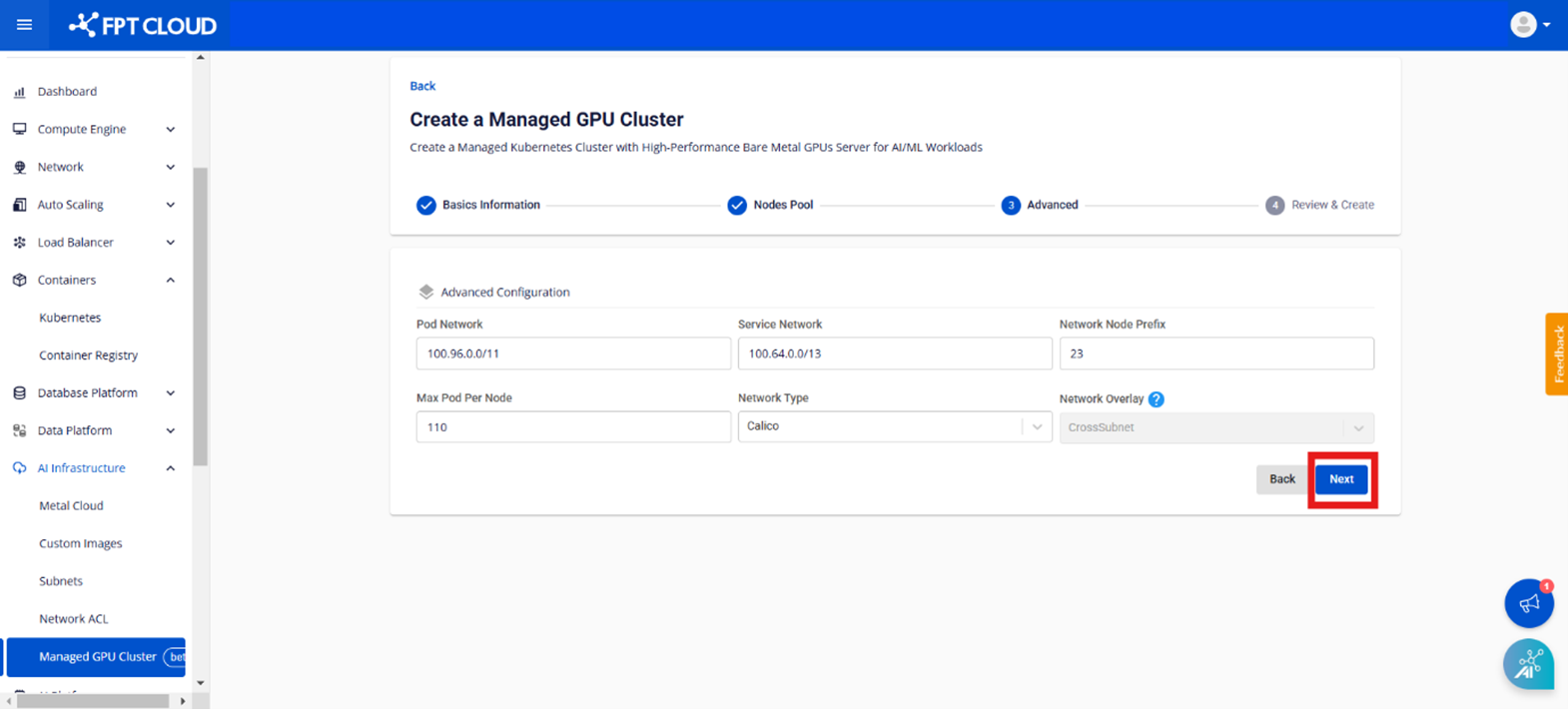
• Pod Network: The network used for Pods in the cluster.
• Service Network: The network used for Services in the cluster.
• Network Node Prefix: The maximum number of Pods per Managed GPU node.
• Max Pod per Node: The CNI type installed for the cluster; only Calico is supported.
Step 5: The Review & Create screen displays all cluster configuration details that the user has set, and the system automatically checks whether the Bare Metal GPU server quota is sufficient to initialize the cluster.
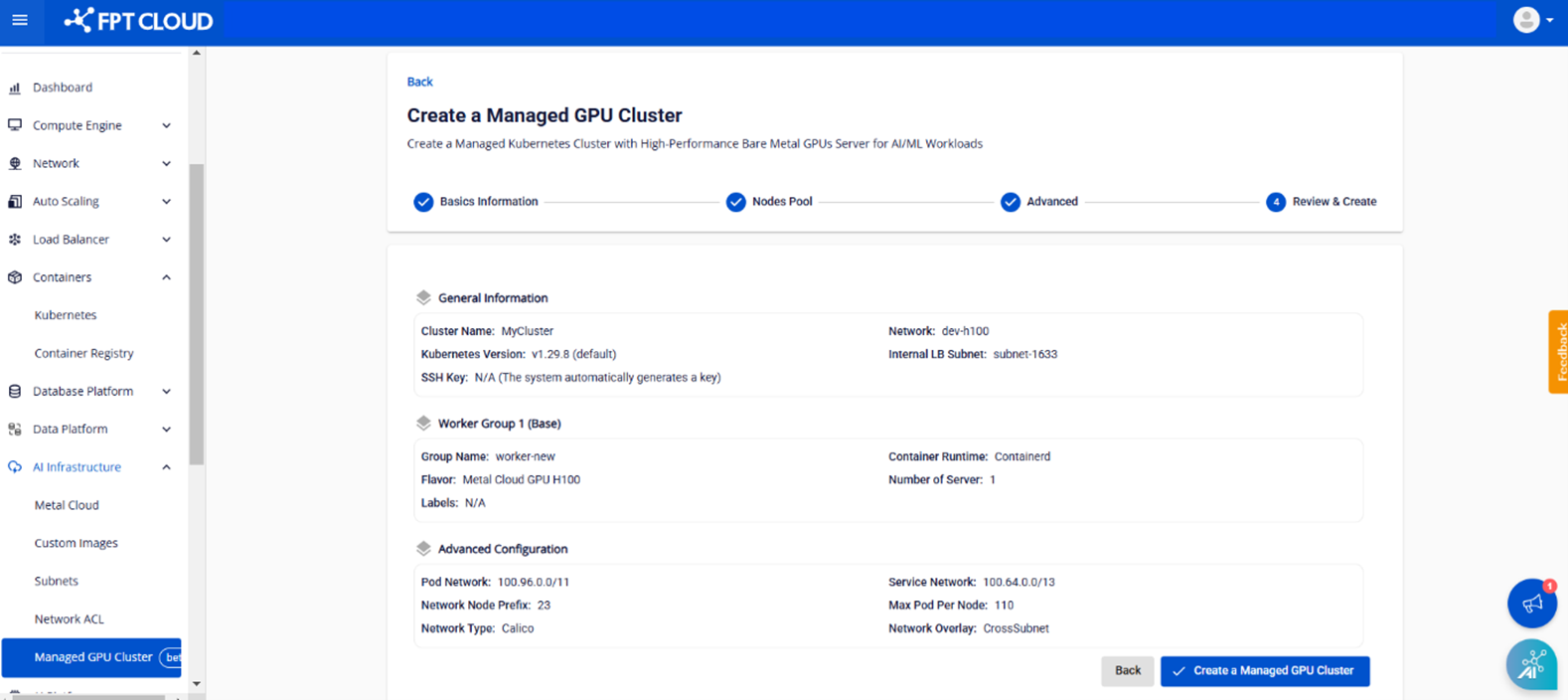
Once the system confirms resource availability, click Create a Managed GPU Cluster to proceed with cluster creation.